JMM 应用总结
公司内接手的老项目近段时间遇到了内存瓶颈,新发版 GC 日志刷个不停,且集中在 YGC,显然有不自然的内存分配,看来内存优化是绕不过了。
在 Java 技术栈内,对内存的分析优化主要集中在堆中,往往需要先使用一些内存分析工具导出堆的一份快照,然后查看是哪些对象在浪费空间,它们可能是非常大的、非常短命的。
除了 JMM,对宿主机的内存管理原理也是有必要掌握的,这样能从底层的角度来进行解释 JMM 的原理,在针对 JMM 进行调参的时候也能更有把握(和运维撕的时候也更不容易被忽悠),鉴于现在的生产环境绝大多数都是 Linux,因此我也会对 Linux 的虚拟内存管理机制作一个简单分析。
JMM 结构分析——JMM 到底说了个什么东西
JMM 隶属于 JVM,主要目标是定义程序中各个变量(非线程私有)的访问规则,即在虚拟机中将变量存储到内存和从内存取出变量这样的底层细节。
- 在多线程编程中,JMM 定义了线程和主存之间的抽象关系:线程之间的共享变量存储在主存(main memory)中,每个线程都有一个私有的本地内存(local memory),本地内存中存储了该线程以读 / 写共享变量的副本,JMM 决定了一个线程对共享变量的修改何时对另一个线程可见。
本地内存是 JMM 的一个抽象概念,并不真实存在,它涵盖了缓存、写缓冲区、寄存器以及其他的硬件和编译器优化。
- 在对象分配中,JMM 定义了对象在方法区内的布局,及对象如何在堆中分配。
JMM 分析工具
- jps 找到目的 Java 进程的 ID,其实就是操作系统的进程 ID,相对来说 jps 更方便一些、自动过滤了无关进程。
- top
比如查看 JVM 里各线程消耗资源的情况:top -p 进程号 -H - jstat
- jinfo
- JConsole
- VisualVM
如果是本地机器,可以用 JConsole、VisualVM 等图形界面工具直接分析内存占用情况,但是这些工具都依赖 JMX、而线上服务器一般不会开放 JMX 端口。
作为代替,可以使用 jmap 导出 heapdump,然后使用 jhat 分析。 - jmap
-heap:显示堆详细信息。
-histo:现实堆中对象统计信息。
-dump:live,format=b,file=heap.hprof:生成 Java 堆转储快照,live 表示只 dump 出存活的对象,format。 - jhat
JMM 出问题的常见现象
- 频繁 YGC;
- 频繁 FGC;
- OOM;
OOM
下面的代码用于演示如何触发 OOM,来自《深入理解 Java 虚拟机》:
1 | /** |
JMM 问题的排查思路
- 查看 GC 日志,判断是否有内存泄露,或者存在代码问题;
开启 GC 日志需要添加 JVM 启动参数-Xloggc:/path/to/gc.log。 - Dump 内存,分析对象结构。
- 编写压测脚本,尝试手动还原线上异常情况。
- 调整 JVM 参数,如新生代、年老代的大小、S0 和 S1 大小比例、垃圾回收器等。
常用调优参数
1 | # server 模式 |
内存估算
JVM 的主要优化思路包括以下两个步骤:
- 合理优化新生代、老年代、Eden 和 Survivor 各个区域的内存大小。
- 尽量优化参数让对象停留在新生代里被回收掉,尽量避免新生代的对象进入老年代。
合理配置的基础是正确预估系统的内存使用模型:
- 每秒占用多少内存?
- 多长时间触发一次 Minor GC?
- 一般 Minor GC 后有多少存活对象?Survivor 能放得下吗?
- 会不会频繁因为 Survivor 放不下而导致对象进入老年代?
- 会不会因为动态年龄判断规则进入老年代?
JVM 的配置要根据具体业务决定,比如,如果业务查询较频繁,一般会设置很多内存缓存,所以老年代比较占空间,如果业务写频繁,数据一般不会在内存中停留太长时间,所以年轻代刷新得会比较频繁,当然,应用的具体属性还是得根据运行时状态来推断,比如 eden 区每次进入 to 区的对象大小以及业务 young gc 的频率。
内存使用模型预估步骤(以订单业务为例):
- 根据下单业务场景热度和线上服务器状况估算单机 QPS;
- 根据单个订单数据量大小计算内存开销;
- 除了下单外订单系统还会有很多订单相关的其他操作,比如订单查询之类的,所以可以往大了估算,比如扩大 10 倍;
比如,以一台 4 核 8G 的机器为例,一般给到 JVM 的内存会达到 4G,剩下空间会留给操作系统、Filebeat 等系统必备基础设施使用。
这 4G 中,堆内存可以给到 3G,其中新生代约 1.5G、老年代也是 1.5G。
每个线程的 Java 虚拟机栈会占用 1M,那么 JVM 里如果有几百个线程大概会有几百 M。
最后再留给永久代 256M 内存,这 4G 内存空间就差不多了。
- 重年轻代、轻老年代
如果应用以大量的临时对象为主,则需要较大的 new 区空间,并且 eden 尽可能的设置大,以存放临时对象。
而持久化对象较少,因此 survivor 区和 old 不需设置较大的 size。
推荐配置为:1
export JAVA_OPTS="-Xms3g -Xmx3g -Xmn2g -server -XX:SurvivorRatio=5 -XX:+UseConcMarkSweepGC -XX:+CMSScavengeBeforeRemark -XX:MaxGCPauseMillis=100 -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -XX:+DisableExplicitGC -verbose:gc -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:-OmitStackTraceInFastThrow -Xloggc:$CATALINA_BASE/logs/gc.log.$DATE -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=1G -Djava.security.egd=file:/dev/./urandom"
- 重老年代、轻年轻代
如果应用大量使用了存活时间较长的对象,例如缓存等,而临时对象较少的应用,则需要较大的 old 区来存放这些对象。
而临时对象较少,则 eden 区不必设置过大,但是由于持久化的对象较多,可能出现对象大量晋升的情况,因此 survivor 区适当增大。
推荐配置为:1
export JAVA_OPTS="-Xms3g -Xmx3g -Xmn1.5g -server -XX:SurvivorRatio=3 -XX:+UseConcMarkSweepGC -XX:+CMSScavengeBeforeRemark -XX:MaxGCPauseMillis=100 -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -XX:+DisableExplicitGC -verbose:gc -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:-OmitStackTraceInFastThrow -Xloggc:$CATALINA_BASE/logs/gc.log.$DATE -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=1G -Djava.security.egd=file:/dev/./urandom"
- 使用 G1
如果应用的性能遇到瓶颈,可以尝试把 GC 算法改为 G1,缩短 STW 时间,但有可能降低吞吐量。1
2DATE=`date +%Y-%m-%d-%H-%M`
export JAVA_OPTS="-Xms6g -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=1G -XX:+UseG1GC -XX:MaxGCPauseMillis=100 -XX:+DisableExplicitGC -verbose:gc -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:-OmitStackTraceInFastThrow -Xloggc:$CATALINA_BASE/logs/gc.log -Djava.security.egd=file:/dev/./urandom -server -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=12113"
什么时候不需要优化 GC
如果满足下面的指标,则一般不需要进行 GC 优化:
- MinorGC 执行时间不到 50ms;
- MinorGC 执行不频繁,约 10s 一次;
- FullGC 执行时间不到 1s;
- FullGC 执行频率不频繁,不低于 10 分钟 1 次
常用调优技巧
- 新生代的 Survivor 区够用吗?
比如新生代为 1.5G,老年代为 1.5G,Eden 区 1.2G,Survivor 区 150M。
如果 Minor GC 后的对象多于 Survivor 区大小,比如 200M,那么必然会出现频繁地让对象进入老年代的情况;
如果少于 Survivor 区大小,比如 100M,因为这是一批同龄对象,直接超过了 Survivor 区空间的 50%,此时也可能会导致对象进入老年代。
对于订单系统业务场景来说,明显大部分对象都是短生命周期的,根本不应该频繁进入老年代,也没必要给老年代维持过大的内存空间,因此如果有出现上述情况,可以考虑把新生代调大(Eden、Survivor 同时变大)、老年代调小,比如新生代 2G、老年代 1G、Eden 区 1.6G、每个 Survivor200M,这样保证了每次 Minor GC 后对象都不到 Survivor 区的一半,大大降低了新生代对象进入老年代的概率。1
2
3
4-Xms3072M -Xmx3072M -Xmn2048M -Xss1M
-XX:SurvivorRatio=8
-XX:PermSize=256M
-XX:MaxPermSize=256M - -XX:MaxTenuringThreshold
这个参数表示对象在新生代连续躲过多少次 Minor GC 后可以进入老年代,一般来说多次躲过的对象都是被@Service、@Controller 之类的注解标注的需要长期存活的核心业务逻辑组件,这个值一般没必要调大,甚至最好调得小一些(默认是 15),不要让对象一直占着宝贵的新生代空间。1
-XX:MaxTenuringThreshold=5
- -XX:PretenureSizeThreshold
JVM 中大对象可以直接进入老年代,因为一般认为大对象是要长期存活和使用的,比如在 JVM 里要缓存一些数据,但是一般来说,给它设置个 1MB 足以,因为一般很少有超过 1MB 的大对象,如果有,一般也是提前分配的一个大数组用来作为缓存使用。1
-XX:PretenureSizeThreshold=1M
- 垃圾回收器
现在最普遍的配置新生代采用 ParNew、老年代使用 CMS,ParNew 的核心参数就是配套的新生代内存大小、Eden 和 Survivor 的比例等,CMS 的核心参数就是老年代的内存大小、进入老年代的条件等:1
2
3
4
5
6
7
8-Xms3072M -Xmx3072M -Xmn2048M -Xss1M
-XX:SurvivorRatio=8
-XX:PermSize=256M
-XX:MaxPermSize=256M
-XX:MaxTenuringThreshold=5\
-XX:PretenureSizeThreshold=1M
-XX:+UseParNewGC
-XX:UseConcMarkSweepGC
例子
- 一次 FullGC
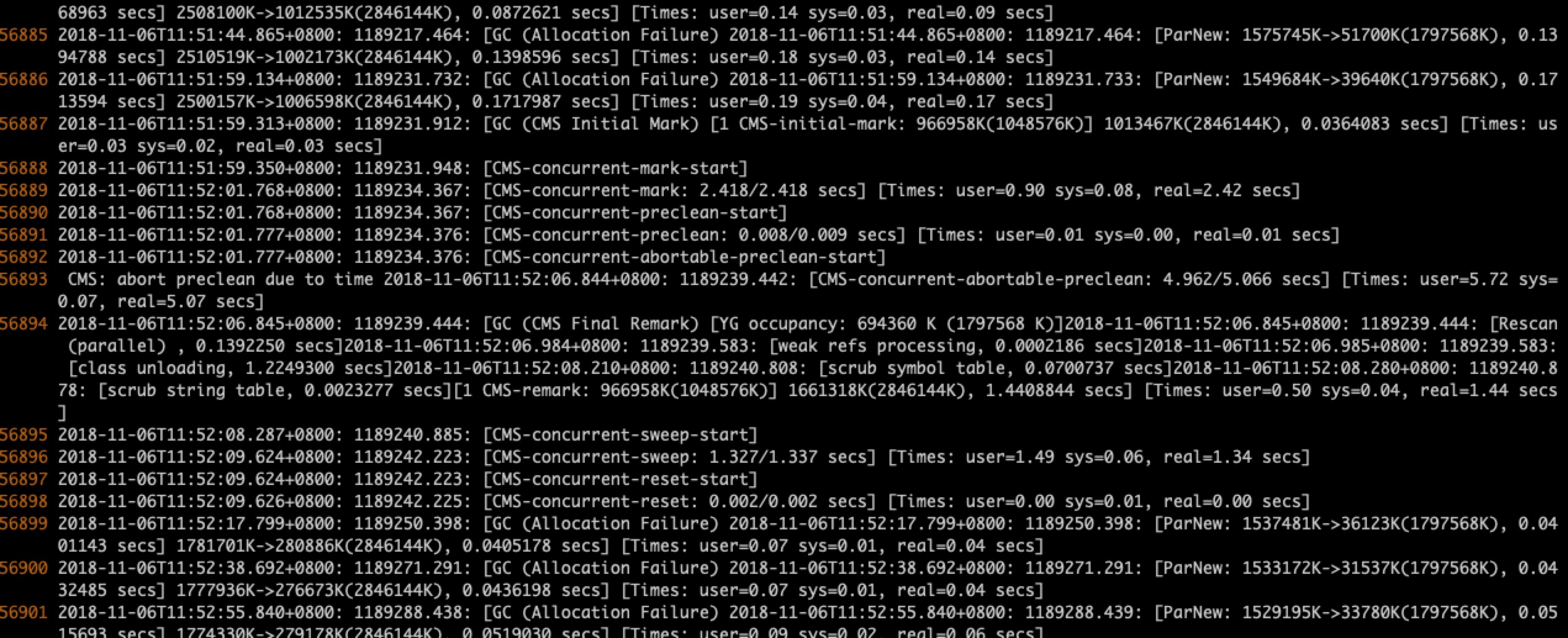
可以看到,remark 阶段消耗了 1.44 秒,而该阶段 STW,应用无法提供服务。
再看之前的 abortable preclean 阶段,该阶段执行了 5.07 秒,仍然没有执行一次 young gc,从而停止该阶段,直接进入 remark 阶段。导致 new 区临时对象过多,remark 阶段长时间的扫描全堆,执行了 1.44 秒
因此对于出现这种情况的业务,可以增加配置 -XX:+CMSScavengeBeforeRemark,在 remark 前强制执行 young gc,减少 STW 时间。
而弊端就是,应用有可能在 abortable preclean 阶段被动触发过一次 young gc,而在 remark 开始时又会触发一次无用的 young gc。