Agent Harness 深度报告
OpenClaw — 架构分析
OpenClaw — 架构分析
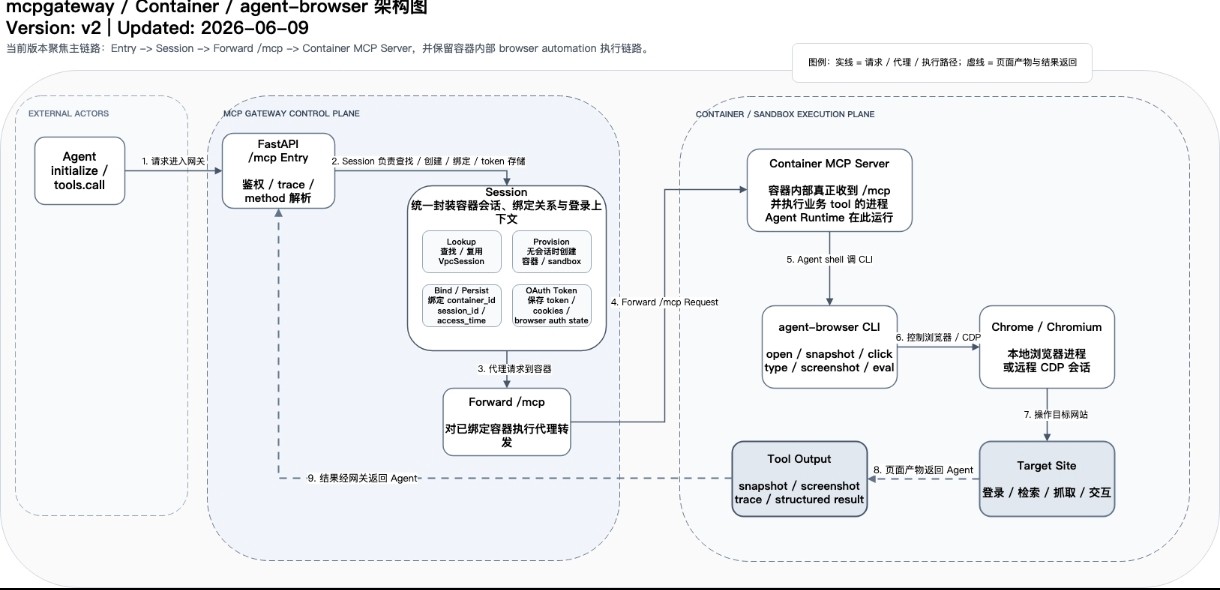
OpenClaw 是一个自托管的开源个人 AI 助手,核心定位是一个 Multi-Channel AI Gateway——将 LLM 能力通过统一的控制面分发到 WhatsApp、Telegram、Slack、Discord、iMessage 等 20+ 消息平台,并支持 macOS/iOS/Android 原生应用和 Web UI。
仓库: https://github.com/openclaw/openclaw · 版本: 2026.3.14 · 许可: MIT
使用文件系统实现Multi Agent间的协作
- 使用文件系统共享数据,如langgraph scratchpad和claude code 子智能体
- 使用文件系统卸载上下文,如langchain
- 使用文件系统实现分布式的agent协作,如manus
claude code构建长期运行Multi-Agent系统的Context-Engineering经验
构建智能体
什么时候需要智能体
- 对任务成功率要求低时采用智能体,否则采用工作流
当前普遍的Agent架构,一般都无法做到比较高的成功率,有时平均成功率低到40、50%,所以Agent结果无法直接应用于业务,而是需要人来干预结果,人来参与进结果的生成,比如编程、写PPT等。 - 任务比较复杂时采用智能体(需要多步推理),否则采用工作流
- 需要解决的任务是复杂而有价值的则使用智能体,否则采用工作流
- 任务异常恢复的代价很低则使用智能体,否则采用Agent的只读模式(不会进行实际上的文件读写或支付等操作)、或采用human in loop模式让人介入进来
参考文档
https://blog.crewai.com/build-agents-to-be-dependable/
https://www.youtube.com/watch?v=XSZP9GhhuAc
构建智能体系统的要素
智能体是一个循环决策的工作流,它自主地或在人类参与的情况下,朝着既定目标进行规划、行动和学习。
- 对所发生事件的记忆
- 影响世界的工具
- 执行审计、约束
- 需要实现的目标
12 Factor Agents - 构建可靠LLM应用的原则
基于12 Factor Agents框架,以下是构建生产级智能体系统的12个核心原则:
Factor 1: 自然语言到工具调用 (Natural Language to Tool Calls)
将自然语言输入转换为结构化的工具调用,确保LLM能够准确理解和执行用户意图。
Factor 2: 拥有你的提示词 (Own your prompts)
不要依赖框架的默认提示词,要完全控制和管理你的提示词,确保它们符合你的具体需求。
Factor 3: 拥有你的上下文窗口 (Own your context window)
主动管理上下文窗口,包括记忆、状态和相关信息,而不是让框架自动处理。
Factor 4: 工具就是结构化输出 (Tools are just structured outputs)
将工具调用视为结构化输出,使用模式验证和类型安全来确保输出质量。
Factor 5: 统一执行状态和业务状态 (Unify execution state and business state)
将智能体的执行状态与业务状态统一管理,避免状态不一致的问题。
Factor 6: 启动/暂停/恢复的简单API (Launch/Pause/Resume with simple APIs)
设计简单的API来管理智能体的生命周期,支持启动、暂停和恢复操作。
Factor 7: 通过工具调用联系人类 (Contact humans with tool calls)
当需要人类干预时,通过工具调用的方式优雅地请求人类帮助。
Factor 8: 拥有你的控制流 (Own your control flow)
完全控制智能体的决策流程,而不是依赖框架的默认行为。
Factor 9: 将错误压缩到上下文窗口 (Compact Errors into Context Window)
将错误信息压缩并整合到上下文窗口中,帮助智能体更好地理解和处理错误。
Factor 10: 小型、专注的智能体 (Small, Focused Agents)
构建小型、专注的智能体,每个智能体负责特定的任务,而不是构建大型通用智能体。
Factor 11: 从任何地方触发,在用户所在的地方见面 (Trigger from anywhere, meet users where they are)
支持多种触发方式,让智能体能够在用户需要的地方出现。
Factor 12: 让你的智能体成为无状态归约器 (Make your agent a stateless reducer)
将智能体设计为无状态的归约器,通过纯函数处理状态转换,提高可靠性和可测试性。
参考文档
https://github.com/humanlayer/12-factor-agents
构建多智能体系统
some problems are too complex, too parallel, or too specialized for one agent to handle alone.
如果单agent的职责过多(比如既需要做PPT、又要通过browser-use实现浏览器检索、又需要使用terminal来写一些脚本来进行复杂运算),每次使用prompt来reasoning时,大模型都需要进行复杂的推理、并在很多工具中进行决策,随着agent的运行,上下文会变得非常复杂不可控。
多智能体系统的难点
多智能系统的难点不在于运行多智能体,而是协同多智能体,如果希望构建一个长期运行的多智能体系统,关键是:
- 任务复杂度过高,需要分解和专业化处理
- 需要并行处理多个子任务
- 要求错误隔离和容错机制
代理是有状态的,错误会累积,,在长时间的执行过程中,Agent会在多次工具调用中保持状态,需要持续处理过程中的错误,然后在出错时,具备中断恢复的能力。 - 需要动态上下文管理和状态协调
核心是上下文工程(Context Engineering)和错误传播控制。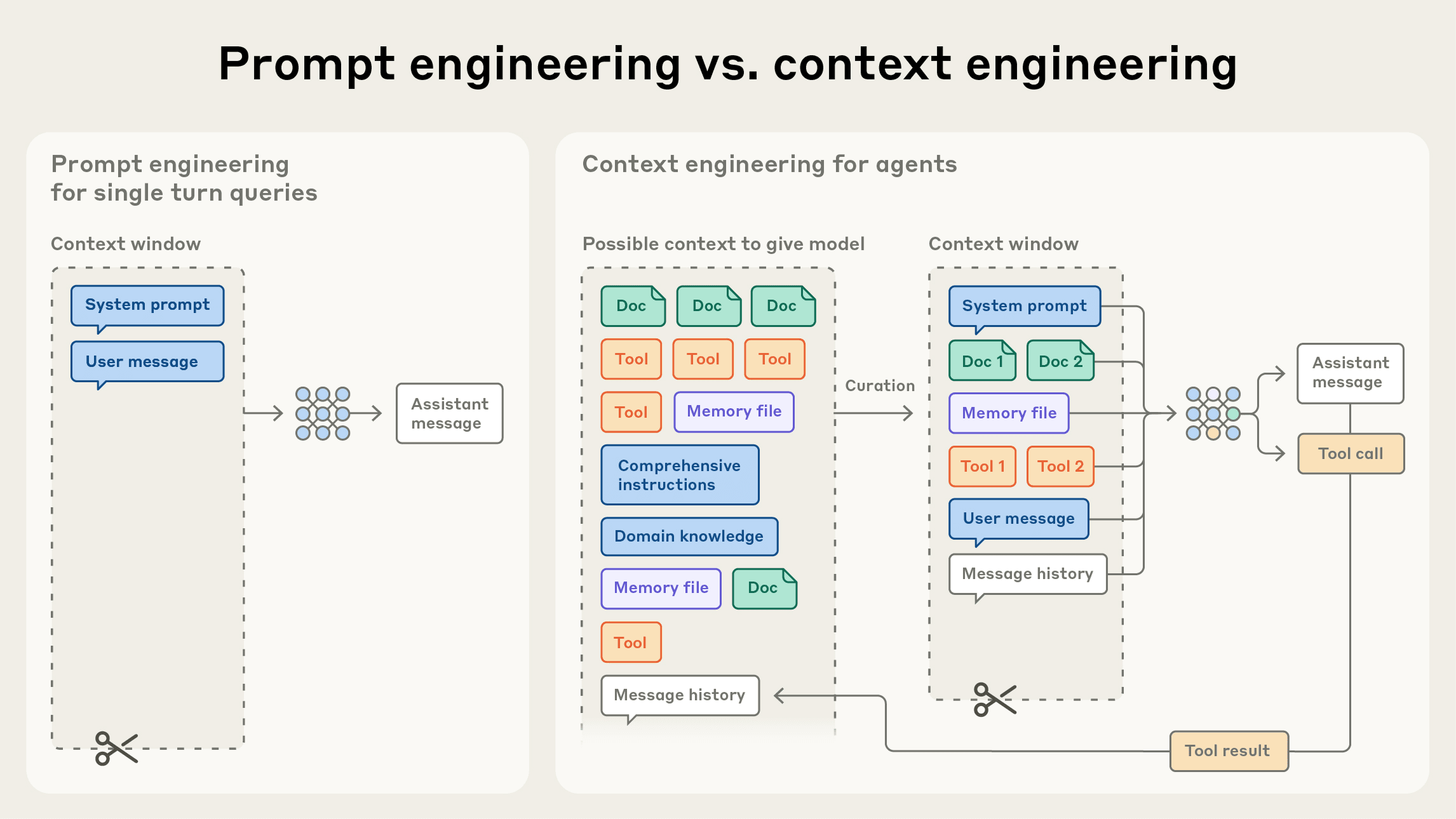
- 上下文压缩:agent运行过程中对历史上下文做summary或prune,去除冗余信息,比如一些
<think>块 - 上下文卸载:将占据大量空间的工具结果存储到外部空间,在需要时加入到上下文中
- 上下文隔离:为多个agent创建相互隔离的上下文,互相之间不会共享窗口
上下文压缩
压缩(Compaction):当对话接近上下文窗口限制时,总结内容并重新初始化新的上下文窗口。
核心原则:
- 保留关键信息(架构决策、未解决的bug、实现细节)
- 清理冗余内容(工具输出、重复消息)
- 维持最小性能损失
实现方式:
- Claude Code:压缩消息历史 + 保留最近访问的5个文件
- 工具结果清理:最安全的轻量级压缩方式
挑战:在保留与丢弃之间平衡,避免过度压缩导致关键信息丢失。
上下文卸载
结构化笔记(Structured Note-taking):智能体定期将笔记持久化到上下文窗口外的存储中,需要时再拉回上下文。
核心优势:
- 提供持久化记忆,开销最小
- 跟踪复杂任务进度,维护关键上下文和依赖关系
- 支持跨工具调用的长期连贯性
实现方式:
- Claude Code:创建待办事项列表
- 自定义智能体:维护NOTES.md文件
- Claude Developer Platform:基于文件系统的记忆工具
应用场景:长期任务中保持状态连续性,避免上下文重置导致的信息丢失。
混合策略(Hybrid Strategy)
在某些场景下,最有效的智能体可能采用混合策略:预先检索一些数据以提高速度,同时根据任务需要自主探索更多信息。决策边界取决于具体任务的特点。
Claude Code的混合模式示例:
- 预先将CLAUDE.md文件直接放入上下文,提供快速访问
- 使用glob和grep等基础工具进行实时环境导航和文件检索
- 有效避免了过时索引和复杂语法树的问题
适用场景:
- 混合策略更适合内容变化较少的场景,如法律或金融工作
- 随着模型能力提升,智能体设计将趋向于让智能模型更自主地行动
- 人工策划的需求将逐渐减少
上下文隔离 - sub-agent
子智能体架构(Sub-agent Architectures):通过专门的子智能体处理专注任务,避免单一智能体维护整个项目状态。
核心设计:
- 主智能体:协调高级计划,专注于结果综合和分析
- 子智能体:执行深度技术工作,使用工具查找相关信息
- 上下文隔离:详细搜索上下文保持在子智能体内,避免污染主智能体
工作流程:
- 子智能体可能使用数万token进行广泛探索
- 返回压缩、精炼的工作总结(通常1,000-2,000 tokens)
- 实现关注点分离,提高系统效率
适用场景:
- 复杂研究和分析任务
- 需要并行探索的场景
- 相比单智能体系统有显著改进
架构示例: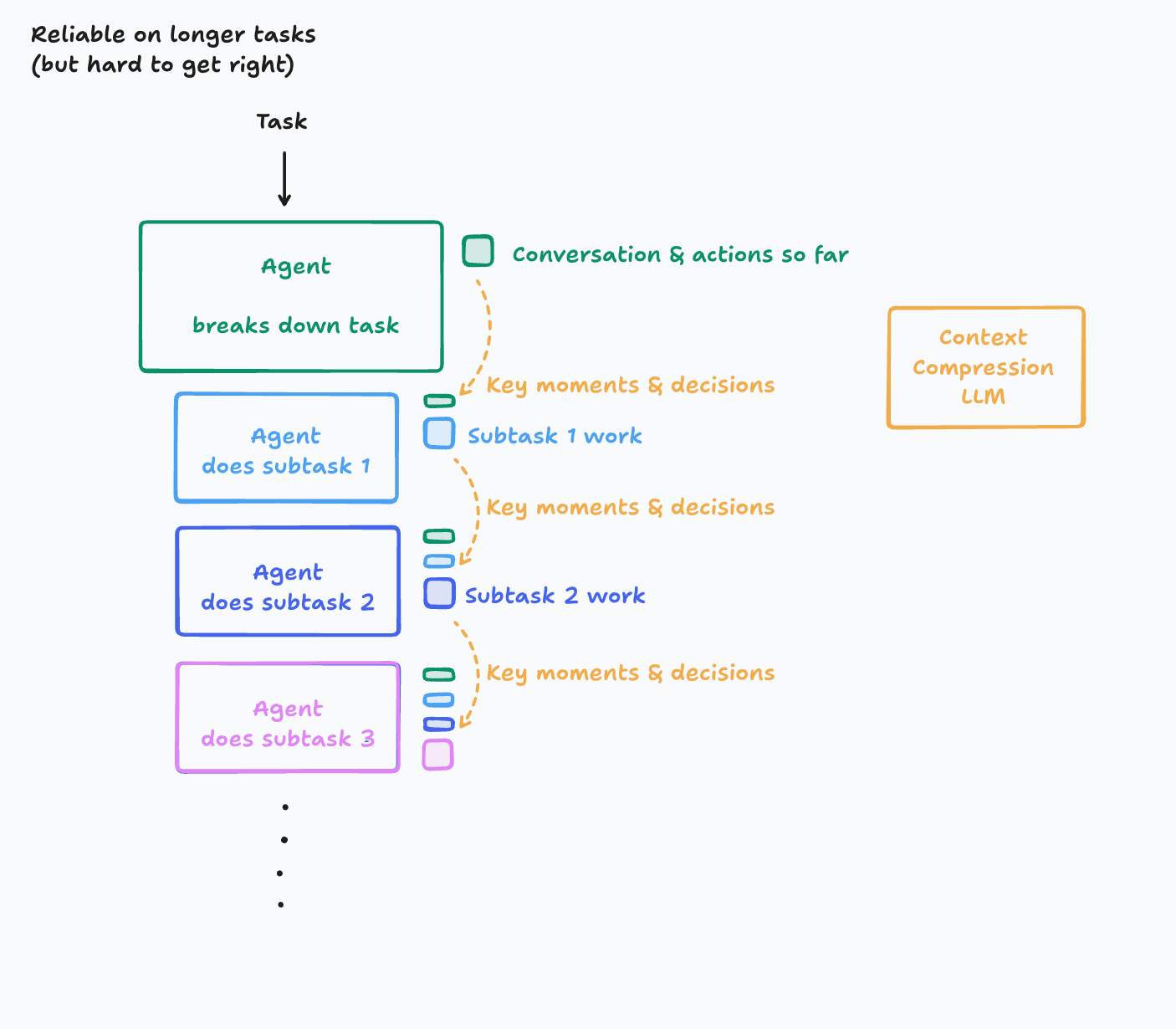
参考文档
https://www.anthropic.com/engineering/multi-agent-research-system?ref=blog.langchain.com
https://cognition.ai/blog/dont-build-multi-agents
https://blog.langchain.com/how-and-when-to-build-multi-agent-systems/
https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
https://www.xiaohongshu.com/explore/6882005d000000001d00d53a?app_platform=android&ignoreEngage=true&app_version=8.92.0&share_from_user_hidden=true&xsec_source=app_share&type=normal&xsec_token=CBIAt7FwVT3rmjUCxeIUs-9z3euUYE-PTih9HgqFRJcJE=&author_share=1&xhsshare=CopyLink&shareRedId=ODc4Rjc2PDs2NzUyOTgwNjY1OTk4Rj1C&apptime=1753439829&share_id=c6e6707db94640ef8bd24b59ea1b466e&share_channel=copy_link
https://github.com/zilliztech/claude-context/blob/master/packages/core/src/context.ts
https://github.com/shareAI-lab/analysis_claude_code/blob/main/claude_code_v_1.0.33/stage1_analysis_workspace/docs/ana_docs/task_agent_analysis.md
https://baoyu.io/translations/decoding-claude-code
多智能体系统的一些范例
https://blog.langchain.com/langgraph-multi-agent-workflows/
https://langchain-ai.github.io/langgraph/concepts/multi_agent/?h=scratchpad
Human in Loop的几种实现方式
human-in-loop是指将人类当成一个tool,在agent的循环执行中,agent可以调用人这个tool来实现输入密码、授予权限等操作。
实现human-in-loop主要取决于两个能力:
- 阻塞通知能力,原地阻塞,等待用户输入,用户输入将通过事件通知的方式来触发流程的继续执行,例如:LlamaIndex和ADK的实现
- 中断恢复能力,在关键执行节点保存执行上下文,让任务能恢复执行,例如:LangGraph的实现
为Agent集成长期记忆
摘要
- 长期记忆是上下文中关键组成部分,长期记忆一般是短期记忆的沉淀,从过去的经验中学习,让用户可以记忆多轮对话的关键信息,得到处理问题的一般模式,
Without proper memory systems, AI applications would treat each interaction as completely new, losing valuable context and personalization opportunities.
- 长期记忆作为RAG的一部分,长期记忆的抽取和检索一般是通过RAG来实现,增强大模型回答领域问题的能力,而预训练专注于一般性问题的回答性能,例如langextract,LightRAG这样的框架
- 使用文件存储长期记忆,按需召回,可以避免上下文超长的问题,例如manus的做法
- 长期记忆又可以分为Semantic、Factual、Episodic,实践中一般会按抽取主体不同,按需建立不同的索引,例如mem0
- 使用ReAct模式的Agent来管理Memory可以提供一些自主性,让Agent根据上下文和多轮的任务来自我进化,例如LangGraph MemoryAgent, QwenAgent, A-Mem, MemU
从短期记忆加工长期记忆
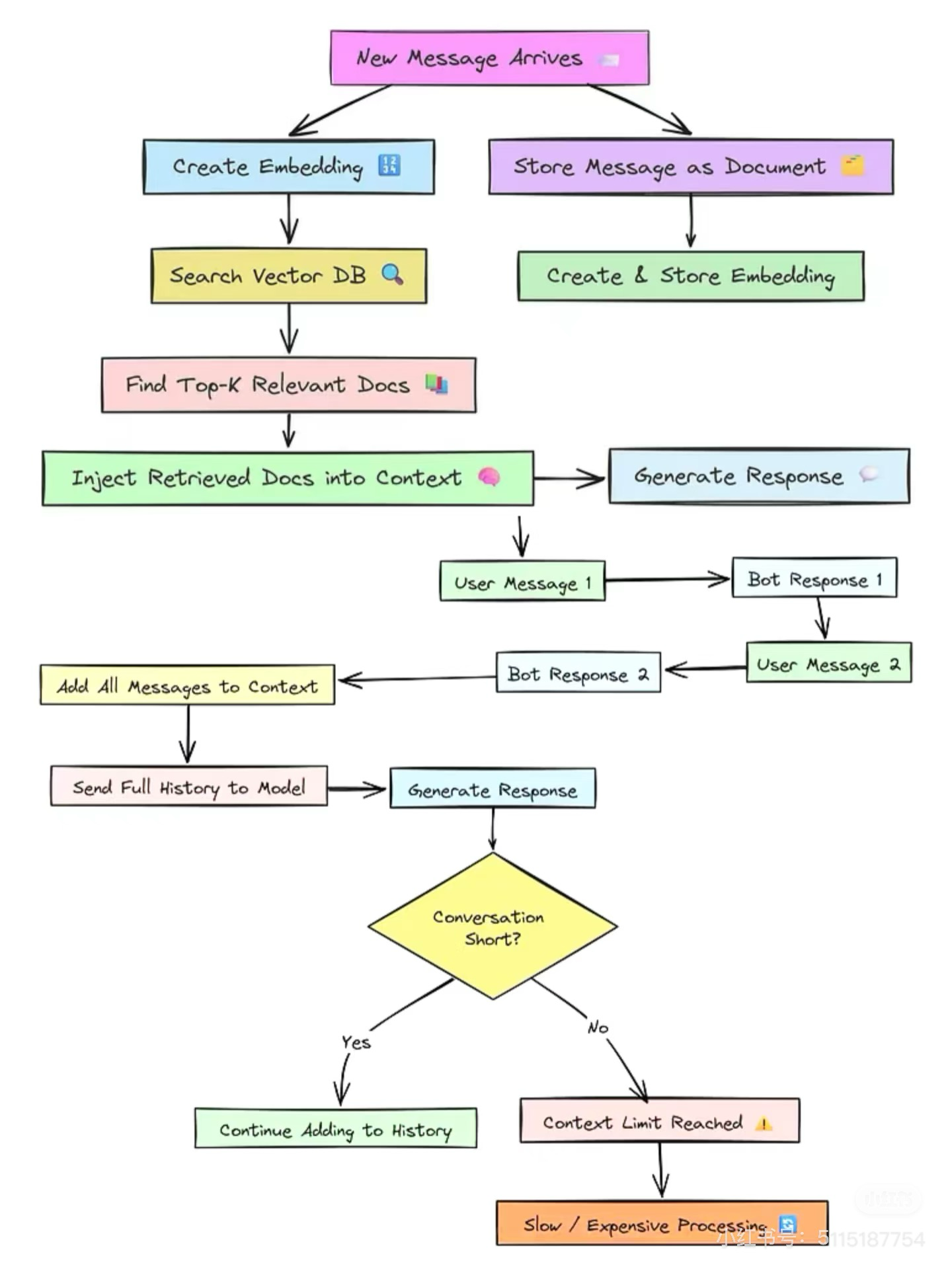
LangGraph - MemoryTemplate

MemoryTemplate是LangChain AI提供的长期记忆服务模板,用于构建和部署可连接到任何LangGraph代理的长期记忆服务,实现用户范围的记忆管理。
- 使用 @functools.lru_cache 定义长期记忆的过期机制
- 使用State定义长期记忆的入参,可见本质上是对短期记忆的持久化处理
1
2
3
4
5class State(TypedDict):
"""Main graph state."""
messages: Annotated[list[AnyMessage], add_messages]
"""The messages in the conversation.""" - memory_graph被标记成一个入口点,相当于一个接口
参考文档
https://github.com/langchain-ai/memory-template
长期记忆的提取是一个RAG模式的实现
langextract
LangExtract是一个Python库,使用LLM从非结构化文本文档中提取结构化信息,基于用户定义的指令。它能够处理各种材料,如临床文本、法律文件、学术论文等,并输出结构化的JSON数据。
核心特性
- 精确源定位:每个提取的实体都包含精确的源文本引用
- 可扩展性:支持处理长文档和并行处理
- 自定义提取:通过提示词和示例控制提取行为,从非结构化文本中提取实体、关系和属性
技术架构
- 基于LLM的信息提取
- 支持自定义模型提供商
- 提供插件系统扩展功能
- 支持本地和云端模型部署
引用链接
MemoryScope
定义一个pipeline来处理记忆
https://github.com/modelscope/MemoryScope
LightRAG
定义
LightRAG是一个简单且快速的检索增强生成(Retrieval-Augmented Generation)系统,专注于提供高效的知识检索和生成能力。
- 智能检索:基于语义相似度的文档检索
- 上下文增强:为LLM提供相关上下文信息
- 知识图谱:利用图结构增强检索效果
- 实时查询:支持实时文档查询和生成
为Memory建立索引和检索
https://blog.langchain.com/semantic-search-for-langgraph-memory/
文件系统作为长期记忆的载体
Manus - 使用文件系统作为终极上下文
现代前沿LLM虽然提供128K+令牌的上下文窗口,但在真实代理场景中仍面临三个痛点:观察结果庞大容易超出限制、长上下文导致性能下降、以及高昂的计算成本。
传统压缩策略虽然能缩短上下文,但过度压缩会导致信息丢失。代理需要根据所有先前状态预测动作,无法预测哪个观察结果在后续步骤中变得重要,因此任何不可逆的压缩都带有风险。
文件系统作为终极上下文解决了这些问题:大小不受限制、天然持久化、代理可直接操作。模型学会按需写入和读取文件,不仅用作存储,还作为结构化的外部记忆。
我们的压缩策略设计为可恢复的:保留URL可移除网页内容,保留文档路径可省略文档内容。这样既能缩短上下文长度,又不会永久丢失信息。
这种基于文件的记忆方式也为状态空间模型(SSM)在智能体中的应用开辟了新可能。SSM虽然缺乏完整注意力机制,但通过将长期状态外部化而非保存在上下文中,其速度和效率可能开启新型智能体时代。

参考文档
https://manus.im/zh-cn/blog/Context-Engineering-for-AI-Agents-Lessons-from-Building-Manus
构建不同的长期记忆索引
Mem0
Mem0将长期记忆划分为不同的类型,并通过api上增加agent_id, user_id, run_id进行索引
记忆类型分类:
短期记忆 (Short-Term Memory)
- 对话历史: 最近的对话消息及其顺序
- 工作记忆: 临时变量和状态信息
- 注意力上下文: 当前对话的焦点
长期记忆 (Long-Term Memory)
- 事实记忆 (Factual Memory): 存储用户信息、偏好和领域特定知识
- 情节记忆 (Episodic Memory): 过去的交互和体验
- 语义记忆 (Semantic Memory): 概念理解及其关系
记忆特征对比:
| 类型 | 持久性 | 访问速度 | 使用场景 |
|---|---|---|---|
| 短期记忆 | 临时性 | 即时 | 活跃对话 |
| 长期记忆 | 持久性 | 快速 | 用户偏好和历史 |
Mem0长期记忆实现方式:
- 使用向量嵌入存储和检索语义信息
- 跨会话维护用户特定上下文
- 实现高效的相关历史交互检索机制
核心价值:
AI系统需要记忆系统实现三个关键目标:
- 在对话中维持上下文
- 从过去的交互中学习
- 随时间构建个性化体验
参考
https://docs.mem0.ai/core-concepts/memory-types
https://docs.mem0.ai/open-source/graph_memory/overview#add-memories
进化的记忆
结合Agent的ReAct范式,实现Agentic RAG,由Agent自主判断记忆的抽取和持久化
MemoryAgent

LangGraph ReAct Memory Agent - 一个具有记忆保存工具的ReAct风格智能体示例。
核心特性:
- 基于ReAct范式的智能体,能够自主判断记忆的抽取和持久化
- 提供
store_memory工具,让智能体保存重要信息供后续使用 - 记忆按
user_id作用域隔离,支持跨对话线程学习用户偏好 - 集成LangGraph Cloud部署,支持API交互
工作原理:
- 智能体从记忆图的
Store读取已保存的记忆 - 调用工具时自动路由到
store_memory节点保存信息 - 支持自定义记忆结构(content + context)
- 可配置不同的LLM模型(默认Claude-3.5-Sonnet)
应用场景:
- 跨会话保持用户偏好记忆
- 重要信息的持久化存储
- 智能体学习能力的增强
参考
https://github.com/langchain-ai/memory-agent?ref=blog.langchain.com
A-mem
https://arxiv.org/pdf/2508.08997
https://github.com/agiresearch/A-mem
https://zhuanlan.zhihu.com/p/1888290059859514793
https://github.com/landing-ai/agentic-doc
QwenAgent
Qwen-Agent采用三级处理框架,先通过BM25检索关键词定位核心段落,再评估分块相关性,最后逐步生成答案,实现百万字级上下文处理。
1. 上下文截断机制
qwen_agent/llm/base.py#_truncate_input_messages_roughly 中实现了基础的上下文长度管理,根据最大长度来截断messages:
- 默认最大输入token数为58000(可通过
DEFAULT_MAX_INPUT_TOKENS配置) - 使用
tokenizer.count_tokens和truncate实时统计token数并按最大token数阈值截断 - 保留系统消息和最新的用户消息
- 从旧消息开始截断,确保最重要的上下文保留
2. Memory对话记忆管理
qwen_agent/agents/memo_assistant.py 实现了对话记忆功能:
- 使用storage工具存储重要信息
- 在对话过程中,你可以随时使用storage工具来存储你认为需要记住的信息,同时也随时可以读取曾经可能存储了的历史信息
- 这将有助于你在和用户的长对话中,记住某些重要的信息,比如用户的喜好、特殊信息、或重大事件等
关于数据存取,有以下两点建议:
- 存一条数据的key尽量简洁易懂,可以用所记录内容的关键词
- 如果忘记存过什么数据,可以使用scan查看记录过哪些数据
此处展示当前你存入的所有信息,因此你可以省去专门读取数据的操作:
1 | <info> |
你的记忆很短暂,请频繁的调用工具存储或读取重要对话内容。
- 自动截断对话历史,保留最近的对话
- 将存储的信息嵌入系统提示中
3. RAG文件知识库管理
qwen_agent/memory/memory.py#_run,messages中的文件会被保存在知识库中,检索和query最相关的部分内容,而不是将整个文件抛给llm:
- 支持多种文件格式(PDF、Word、Excel、TXT等)
- 使用RAG(检索增强生成)技术
- 可配置的检索策略和关键词生成
4. DialogueRetrievalAgent - 超长对话管理
qwen_agent/agents/dialogue_retrieval_agent.py:
- 将长对话存储为文件
- 基于检索的历史对话查询
- 会话级别的历史管理

5. VirtualMemoryAgent - 虚拟内存管理
qwen_agent/agents/virtual_memory_agent.py 针对messages中出现的文件名,自动通过deepsearch的方式来检索:
- 先由llm来决定使用什么工具处理这些文件,然后调用这些工具
- 直到达到最大调用次数20次,或不再产生新的toolcall
- 自动检索外部资源
- 动态更新上下文知识
- 智能工具调用
参考文档
https://qwenlm.github.io/zh/blog/qwen-agent-2405/
https://github.com/QwenLM/Qwen-Agent
https://community.modelscope.cn/682d45a3870cef736060aaef.html
MemU
MemU采用背景进程对记忆进行加工和抽取,并建立联系存储到图库中,形成自我进化