公司大佬关于编码规范的一次分享
参考
由来
公司比较看重这批新员工(基本来自 985 院校),做了比较多的培训,从公司文化到衣着讲究都专门开了课,很切合应届毕业生的需求(强制参加的…)。
规范类似设计模式,是对最佳实践的总结,有点收获,这里把还记得的部分总结一下。
Java 编码规范
基本没听(其实是因为不知道下午要考试),内容和阿里 Java 规范很接近,有时间考个证书。
用户体验分享
这个大佬比较惨了,大家都是程序员、还都是偏后台的那种,讲课时间还是刚吃完饭那会,大家不是特别能接受,反正我是没听进去。
数据库规范
公司一个架构师大佬讲的,大部分内容仍然来自阿里 Java 规范,掺杂了一些干货。
遵守规范有什么好处
- 约定大于配置(这个理念是 SpringBoot 的基础),规范属于一种约定。
- 提高沟通效率
- 提升后续管理效率
基础
设置
- 使用 UTF8MB4。
- 注释很重要。
- 数据库内大小写不敏感,像 MySQL、Oracle 都是大小写不敏感的,如果出现敏感的情况注意设置成不敏感的。
命名
- 尽量取有意义的名字
- 如果有多个单词使用下划线分割
- 长度不要过长,如果设置得过长了,后面创建该表的备份表、表名末尾带上一些特殊的后缀,可能会超出数据库对表名长度的限制。
设计
- 尽量达到 3NF
达到 1NF 和 2NF 是理所当然的,BCNF 又太严格了,会把表结构拆得过碎了,由此引入的多表关联会严重影响 DCL 效率,4NF 更是会把表结构拆稀碎了,达到 3NF 是比较理想的,但是不排斥使用 NoSQL 后产生的冗余。 - 逻辑删除而不是物理删除
好处是可以反悔,坏处是表里数据会多很多。
但是实践表明删除是很少被使用的,换句话说,被删除的数据相对总数来说是很少的,比如说我们把商品加到购物车里一般都会买掉而不是删除了,因此我们更倾向于使用逻辑删除。当然也不能排除有些业务删除是常用的,那就另说了。
补充:其实我觉得完全可以另开一个表来存被逻辑删除的数据,我在毕设中就是这么做的。 - 为数据加上时间戳
加上时间戳的主要目的是实现数据的增量同步,比如将数据同步到搜索系统(一般是 Elasticsearch)中,全量同步是无法忍受的。
补充:时间戳还可以当作乐观锁。 - 合理利用 char
varchar 能满足大部分用到字符串的场景,但是 varchar 的效率是不如 char 的,对于手机号、身份证号这种固定长度的属性完全可以使用 char 类型保存。 - 复杂的处理逻辑放到应用层而不是持久化层,不要用触发器、存储过程、视图,因为在云计算环境下应用层的扩展成本要远低于持久化层。
补充:视图其实还是可以用一下的,比如给另一个部门查点数据,又不会暴露数据库的真正结构。
补充:数据库设计理论
元组/行:一个持久化对象。
属性/字段/列:某类持久化对象的属性,属性集一般使用 U 表示。
超键:能唯一标识一条元组的属性集。
候选键:不包含多余属性的超键。
主键:被用户选作元组标识的候选键。
主属性:构成候选键的属性。
函数依赖(FD):由业务确定的属性之间的依赖关系,即由一组属性可以唯一确定另一组属性。
关系模式(R(U)):指在属性集中存在的所有函数依赖。
平凡函数依赖:在 R(U)中存在 X→Y,若 Y 包含于 X,则称 X→Y 为平凡函数依赖。
完全依赖:在 R(U)中,如果 X→Y,并且对于 X 的任何真子集 X’都有 X’-/->Y’,则称 Y 完全依赖于 X,记作 X→Y。比如确定一批书的印刷时间需要给出版次和印次,不管是单独给出版次或印次都无法确认这批书。
部分依赖:与完全依赖相反,如果 X→Y,且 X 中存在一个真子集 X’,使得 X’→Y 成立,则称 Y 部分依赖于 X。比如学号和姓名可以确定一个学生,但其实学号就可以确定一个学生了。
传递依赖:指的是形如 X→Y→Z 的函数依赖。
多值依赖(MVD):原始定义比较难理解,用一个特殊情况来说明,就是在同一个表里存在 X:Y、X:Z 分别是 1 对多关系,即有 Y→X、Z→X,比如[课程, 学生, 先修课]是一张表,其中课程对学生、课程对先修课都是 1 对多关系。
1NF:不能有复合字段(不可分的原子值)。
实现方法:如果有,则拆成多个字段。
例子:一个人可能有多个联系电话,比如手机号、固话等,应该被拆分到多列内,或者多行保存同一人的多个电话。
| 身份证号 | 姓名 | 手机号 | 固定电话 |
|---|---|---|---|
| 3303012313 | 赵 | 18012341234 | 123-12341234 |
| 身份证号 | 姓名 | 手机号 |
|---|---|---|
| 3303012313 | 赵 | 18012341234 |
| 3303012313 | 赵 | 123-12341234 |
缺陷:
2NF:实体属性完全依赖于主键、不能仅依赖主键的一部分属性(严格地说,非主属性完全依赖于候选键)。
实现方法:如果存在对主键的部分依赖,则拆出来作为一个新实体。
例子:
缺陷:
3NF:非主键属性不能间接依赖于主键(严格地说,不能有非主属性对候选键的传递依赖)。
实现方法:如果存在上述传递依赖,则将依赖的两个非主属性拆出成为新表,原表和新表之间是 1 对多的关系。
例子:
缺陷:
BCNF:消除任何属性对候选键的传递依赖(在 3NF 的基础上,不允许候选键属性传递依赖于候选键的属性)。
实现方法:同 3NF。
例子:
缺陷:
4NF:消除非平凡且非 FD 的多值依赖。
实现方法:
例子:
缺陷
SQL 编写
- 明确指出所有列,不要省略或使用通配符,比如:
1
2select * from t;
insert into t values('1', 2); - 连接操作给出表的别名,否则容易混淆
性能优化
- 分库分表
将数据从一张表拆到多张表,后续再将这些表转移到多个数据库实例内,一般情况下可以减少单个数据库的压力,提升整体性能。常见的拆库方法如:- 按业务纬度分表(垂直拆分):将负责不同业务的表拆到不同库中。
- id hash(水平拆分):对业务数据 id 求模 hash(id) % n,hash 函数是自定义的,如果 id 是数值可以直接返回 id 本身,如果是字符串可以取前几位的和(遍历每一位太慢了),n 表示我们需要将数据拆到几张表里。
日期 hash(水平拆分):将不同月甚至日的数据分散到不同的库中。
特殊 hash(水平拆分):按照某个特定的字段求模,或者根据特定范围段分散到不同的库中。 - 读写分离:将数据拷贝到多个读库和写库内,读库加上索引,而写库不需要,这样,当然写库还需要通过某种机制将数据增量更新到读库内。
- 冷热分离:将冷数据分离出去,比如微信聊天中 3 天前的数据就可以算作冷数据,这部分数据比较少用到,分离出去后可以提高查询最近聊天数据的响应效率。
- NoSQL
NoSQL 常用于冗余数据,可以避免复杂的关联查询。 - 索引
索引可以避免全表扫描,正确使用索引可以大大提高查询效率,但要注意函数可能导致索引失效,分析 SQL 语句问题的主要工具是执行计划。 - 分页
- 数据库分页优于内存分页
- 分页前最好先过滤
- order by 子句中最好不要使用会重复的字段(比如 name 就有可能重名)
- 海量数据下可以只现实前 500 条数据,而不显示总条数和页数(百科和 Google 搜索都是这么做的)。
补充:缓存命中率和缓存淘汰
缓存命中率 = 查询命中数 / 总查询数
缓存命中率是度量缓存有效性的常用参数,为了提高缓存命中率,最好对不变数据进行缓存。
缓存淘汰是在服务器内存不够用时触发的,将一些价值较小的数据从缓存中淘汰,减少不必要的 swap,提升内存的有效利用率。
缓存淘汰还有一个问题:是先写入还是先淘汰呢?
首先看先写入再淘汰的情况,如下图所示。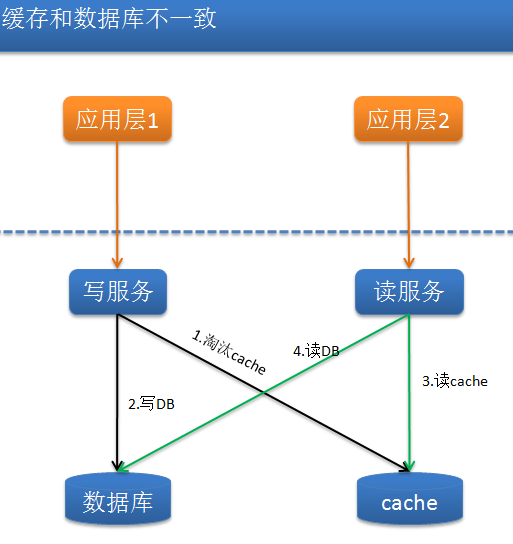
我们交换操作 3 和 4 的顺序,第一步数据库操作成功,第二步如果淘汰缓存失败,则会出现 DB 中是新数据,Cache 中是旧数据的情况,即产生了数据不一致的问题。
然后是先淘汰再写入的情况,同样如上图所示。
写和读操作是并发执行的,应用实例 1 首先发起对缓存的淘汰,应用实例 2 读缓存 miss,于是从数据库读,而应用实例 1 这才将新值写入数据库,此时实例 2 得到的数就是脏数据了,注意在分布式环境下这种执行顺序完全是有可能的。
补充:执行计划
操作规范
- 变更需要明确范围
- 为上线预留时间和空间
- 给最专业的人进行评估
- 错峰操作
考试
考试题
一、单选题(每道题 2 分,共 12 分)
1、现有一张系统用户操作日志表,合理命名应该是( )
A、XTYHRZB
B、SysUserOpLog
C、Sys_User_Oplog
D、SYS_T_USER_OPLOG
2、下面数据库设计不符合规范的是( )
A、大数据量表进行分库分表
B、为了方便查看,表中使用明文存储用户密码
C、使用数字格式存储时间
D、将 json 格式数据存储到 Nosql 数据库
3、下面 SQL 编写不符合规范的是( )
A、select column1, column2 from table1
B、select column1, b.columna from table1, table2 b where column1 = b.columna
C、insert into table1(column1,column2) values(?,?)
D、update table1 set column1 = ‘aaa’ where id = ‘001’
4、下面关于性能优化不正确做法的是( )
A、尽量避免一条 SQL 从大于 4 张表中取数
B、如果一条 SQL 有三层以上的嵌套查询,在设计上考虑解决
C、为了提升代码执行效率,大量的公式运算交给数据库后端运行
D、为常用的分组排序字段建立索引
5、下面不正确的索引建立方法的是( )
A、业务表唯一标识字段必须制定唯一索引
B、只要是查询可能用到的字段,都要建立索引
C、尽量使用数据量少的索引
D、索引列上不使用函数计算
6、下面数据库操作符合规范的是( )
A、为了方便,应用程序使用超级管理员账号
B、为了快速解决问题,直接在后端数据库中修改业务数据
C、修改表结构告知影响人员,并预留一定时间评估、审核
D、程序测试完成后直接上线新功能
二、多选题(每道题 6 分,共 60 分)
1、关于领域模型命名,下列哪些说法符合规范:( )
A、数据对象命名:xxxDO,xxx 即为数据表名,例如:ResellerAccountDO。
B、数据传输对象:xxxDTO,xxx 为业务领域相关的名称,例如 ProductDTO。
C、展示层对象:xxxVO,xxx 一般为网页名称,例如 RecommendProductVO。
D、POJO 是 DO/DTO/BO/VO 的统称,命名成 xxxPOJO。
2、关于代码注释,下列哪些说法符合规范:( )
A、所有的抽象方法(包括接口中的方法)必须要用 javadoc 注释。
B、所有的方法,包括私有方法,最好都增加注释,有总比没有强。
C、过多过滥的注释,代码的逻辑一旦修改,修改注释是相当大的负担。
D、我的命名和代码结构非常好,可以减少注释的内容。
3、关于类命名,下列哪些说法符合规范:( )
A、抽象类命名使用 Abstract 或 Base 开头。
B、异常类命名使用 Exception 结尾。
C、测试类命名以它要测试的类的名称开始,以 Test 结尾。
D、如果使用到了设计模式,建议在类名中体现出具体模式。例如代理模式的类命名:LoginProxy;观察者模式命名:ResourceObserver。
4、关于加锁,下列哪些说法符合规范:( )
A、可以只锁代码区块的情况下,就不要锁整个方法体。
B、高并发的业务场景下,要考虑加锁及同步处理带来的性能损耗,能用无锁数据结构,就不要用锁。
C、能用对象锁的情况下,就不要用类锁。
D、加锁时需要保持一致的加锁顺序,否则可能会造成死锁。
5、关于方法的返回值是否可以为 null,下列哪些说法符合规范:( )
A、方法的返回值可以为 null,如果是集合,必须返回空集合。
B、方法的返回值可以为 null,不强制返回空集合,或者空对象等。
C、方法实现者必须添加注释,充分说明什么情况下会返回 null 值。
D、防止 NPE 是调用者的责任。
6、关于控制语句,下列哪些说法符合规范:( )
A、推荐 if-else 的方式可以改写成卫语句的形式。
B、尽量减少 try-catch 块内的逻辑,定义对象、变量、获取数据库连接等操作可以移到 try-catch 块外处理。
C、if ( condition) statements; 单行语句不需要使用大括号。
D、在一个 switch 块内,都必须包含一个 default 语句并且放在最后,即使它什么代码也没有。
7、关于捕获异常和抛异常,下列哪些说法符合规范:( )
A、如果需要捕获不同类型异常,为了方便处理,可以使用 catch(Exception e){…}。
B、不要捕获异常后不处理,丢弃异常信息。
C、捕获异常与抛异常,必须是完全匹配,或者捕获异常是抛异常的父类。
D、异常定义时区分 unchecked / checked 异常,避免直接使用 RuntimeException 抛出。
8、关于变量和常量定义,下列哪些符合规范:( )
A、Long a=2L;//大写的 L。
B、Long a=2l; //小写的 l。
C、常量只定义一次,不再赋值,所以不需要命名规范。
D、不要使用一个常量类维护所有常量,应该按常量功能进行归类,分开维护。
9、数组使用 Arrays.asList 转化为集合,下列说法哪些正确的:( )
A、数组元素的修改,会影响到转化过来的集合。
B、数组元素的修改,不会影响到转化过来的集合。
C、对于转换过来的集合,它的 add/remove/clear 方法会抛出: UnsupportedOperationException。
D、Arrays.asList 体现的是适配器模式,只是转换接口,后台的数据仍是数组。
10、关于并发处理,下列哪些说法符合规范:( )
A、线程资源必须通过线程池提供,不允许在应用中自行显式创建线程。
B、同步处理时,能锁部分代码区块的情况下不要锁整个方法;高并发时,同步调用应该考虑到性能损耗。
C、创建线程或线程池时,推荐给线程指定一个有意义的名称,方便出错时回溯。
D、推荐使用 Executors.newFixedThreadPool(int x)生成指定大小的线程池。
三、问答题(4 道题,共 28 分)
1、人力云(HR)业务需要建立人员表(含姓名、年龄、性别)和人员工作情况表(含工作开始时间、工作结束时间、工作单位、工作简介),请写出具体的建表语句。(8 分)
2、请列举你所了解的分库分表方式。(6 分)
3、现有业务需求要修改表结构,开发库已经修改测试完成,需要在生产库同步修改并发布新程序,请问你具体的步骤。(5 分)
4、现在有一张表 tablea,主键 key1,只有主键含有唯一索引,字段 columna,columnb,columnc,数量级 100 万,现在按照主键升序,每页 100 条分页,请写去取出第 900000 到 900100 条数据的 SQL 语句。(9 分)
答案&分析
一、单项选择
1.D 数据库大小写不敏感,应该全部用大写
2.B 选项 C 时间用数字格式存储,可以方便最后的国际化时区转化
3.B 连接语句要对每个表给出别名,对每个字段的使用都要带上表别名,否则有子查询的情况下,语句可能出现执行计划错误,甚至结果集错误。
4.C 选项 B 建议使用 NoSQL 缓存或其他可以在架构上优化的措施来减少复杂的数据库操作;选项 C 公式运算容易使得索引失效因此不建议在数据库中使用;选项 D 中的建议是因为 order by 和 group by 会使用到索引。
5.B 选项 B 索引是有代价的,对于一些值重复性较大的列最好不建索引;选项 C 也是考虑在写操作时更新索引会拉低性能。
6.C 操作一般是越谨慎越好,数据库操作最好交给专业人员来做(DBA),选项 B 是为了避免数据库出问题时互相甩锅。
二、多项选择
1.ABC 选项 C 我似乎没选,因为把 VO 当成 DO 来用了,而且现在开发都是前后台分离,很少用到页面模板;选项 D 中 POJO 确实是 DO/DTO/BO/VO 的统称,但不能把所有都命名成 XxxPOJO,会分不清该类的职责。
2.ACD 一般接口和抽象类里的抽象方法需要加上注释,而类里面的私有方法没有这个要求,也要避免注释过多的情况。
3.ABCD
4.ABCD 使用锁时要考虑锁的粒度、性能等特性,同时应该避免死锁等问题。
5.BCD 我和大部分人一样非常厌恶方法返回 null,尽量返回空集合或空对象能减少很多烦恼,但是手册中认为方法可以返回 null,防止 NPE 是调用者的责任,我觉得原因很大程度上是因为难以避免远程调用失败、序列化失败、运行时异常等场景返回 null 的情况。
6.ABD 选项 A 卫语句指的是处理完一个分支后直接返回;选项 B 强调我们分清稳定代码和非稳定代码,不要将不会出错的稳定代码也加到 try 中,这是不负责任的。
7.BCD 异常最好有业务含义,能提高后期排错效率。
8.AD 选项 B 不规范是因为 l 和 1 容易混淆。
9.ACD 最好看一下 Arrays.asList()源码。
10.ABC FixedThreadPool 不推荐使用,因为其允许的请求队列长度为 Integer.MAX_VALUE ,可能会堆积大量的请求,从而导致 OOM 。
三、简答题
第一题:表名和字段名按规范,表名前缀 HR,使用有意义的单词,单词间用_分割,有中文注释。
第二题:读写分离,冷热分离,按照特定业务纬度分表,使用 ID Hash 取余平均分表等。
第三题:
1、明确影响范围
2、预留应变空间时间
3、交由专家评估合理性和性能
4、脚本交由专人在生产库执行,记录;
5、错峰操作。
第四题:参考规范 3 性能优化 22 ,或者先查询 id,在根据 id 查询数据等都可。
补充:后一个方法为什么可行呢?因为规范要求所有删除都是逻辑删除,能保证库里的数据 id 是从 1 到 1000000 排列的。
反思
有的题目比较抠细节,但是上课好好听应该不难。
大部分规范都取自阿里 Java 编码规范,但很多数据库优化策略很有见地,在日后多作总结。