Linux 脚本基础
记录一些平时看到或用过的 shell 脚本技巧和代码片段。
记录一些平时看到或用过的 shell 脚本技巧和代码片段。
Kubernetes Master 主要负责管理集群,它会协调集群内的所有活动,包括:scheduling applications, maintaining applications’ desired state, scaling applications, and rolling out new updates。
Master 实际上是三个进程的集合,它们运行在集群的一个 Master Node 上,这三个进程包括:
Node 是一台虚拟机或物理电脑,在集群中作为 Worker。Master 管理 Cluster,而 Node 则管理应用。
每个 Node 都有一个 Kubelet,是管理 Node 的媒介,且负责与 Kubernetes Master 进行交互。
每个 Node 还需要有工具来处理容器操作,比如 Docker 或 rkt。
一个生产环境的 cluster 必须由至少 3 个 Node 组成。
节点代理,负责和 Kubernetes Master 交互:
运行于每个 Node 上的一个网络代理,可以执行简单的 TCP、UDP、SCTP 流转发或提供多后端进程的负载均衡。
相当于在主机和 Cluster 之间创建了一个连接,让我们能直接访问 API。
一个或多个应用容器集合的抽象,并且包含一些共享资源,包括:
Pod 建模了一种“logical host”,可以同时运行多种不同的容器。
当 Pod 所处的 Node 挂了,ReplicaSet会动态地创建新 Pod 来使得 Cluster 回到原来的状态。
Service 定义了 Pod 的逻辑集合及其访问规则,虽然每个 Pod 都有一个唯一的 IP 地址(Cluster 范围内),但是如果没有 Service 的话这些 IP 也是没法暴露到 Cluster 外的,可以通过指定 ServiceSpec 中的type来指定暴露服务的方式:
<NodeIP>:<NodePort>. Superset of ClusterIP.externalName in the spec) by returning a CNAME record with the name. No proxy is used. This type requires v1.7 or higher of kube-dns.负责创建和更新应用实例,创建 Deployment 后,Master 会持续监听并在各 Node 中调度应用实例,一旦有实例挂掉或被删掉,Deployment controller 就会用 Cluster 中另一 Node 上的实例取代之。
可以采用kubectl命令来和 Cluster 交互,kubectl最常用的操作只有如下 4 种:
例子中使用minikube创建 Cluster,然后使用kubectl来和创建的 Cluster 交互:
1 | minikube version |
1 | # 创建Deploymnet |
1 | # 创建proxy实例 |
1 | # 所有应用发送给STDOUT的信息都会成为Pod容器的日志 |
1 | # 查看Pod内的环境变量 |
1 | # 查看Service |
1 | # 8080其实是集群内的一个逻辑端口,可以通过以下命令获取Node上暴露的端口 |
1 | # 先获取Pod的名字 |
1 | # 删除一个Service |

上图来自官网教程,Scaling 即修改 Deployment 中的 Pod 数。
1 | # 先看下部署了几个Pod |
1 | # 使用一个NODE_PORT环境变量来保存Node暴露的端口 |
1 | # 再运行一次scale命令来缩小ReplicaSet |
1 | # 先看看Cluster里有啥 |
1 | # 确认应用正在运行中 |
1 | # 设置镜像进行更新,但是这个镜像的v10版本是不存在的,因此会引起更新失败 |
在 awk、sed、cut 三个命令中,awk 是功能最强大的,基本能实现所有字符串操作,平时常用于较复杂的日志分析,不过比起别的命令来也会相对复杂一点。
慢,效率低,占用系统资源高,易被攻击
TCP 在传递数据之前,要先建连接,这会消耗时间,而且在数据传递时,确认机制、重传机制、拥塞控制机制等都会消耗大量的时间,而且要在每台设备上维护所有的传输连接,事实上,每个连接都会占用系统的 CPU、内存等硬件资源。 而且,因为 TCP 有确认机制、三次握手机制,这些也导致 TCP 容易被人利用,实现 DOS、DDOS、CC 等攻击。


一开始,客户端和服务端都处于 CLOSED 状态。先是服务端主动监听某个端口,处于 LISTEN 状态。然后客户端主动发起连接 SYN,之后处于 SYN-SENT 状态。服务端收到发起的连接,返回 SYN,并且 ACK 客户端的 SYN,之后处于 SYN-RCVD 状态。客户端收到服务端发送的 SYN 和 ACK 之后,发送 ACK 的 ACK,之后处于 ESTABLISHED 状态,因为它一发一收成功了。服务端收到 ACK 的 ACK 之后,处于 ESTABLISHED 状态,因为它也一发一收了。
从连接建立的流程中可见,三次握手除了双方建立连接外,还能确定TCP包的序号问题。
总而言之:
TCB 传输控制块 Transmission Control Block,存储每一个连接中的重要信息,如 TCP 连接表,到发送和接收缓存的指针,到重传队列的指针,当前的发送和接收序号。
一些问题:

假设 Client 端发起中断连接请求,也就是发送 FIN 报文。Server 端接到 FIN 报文后,意思是说”我 Client 端没有数据要发给你了”,但是如果你还有数据没有发送完成,则不必急着关闭 Socket,可以继续发送数据。所以你先发送 ACK,”告诉 Client 端,你的请求我收到了,但是我还没准备好,请继续你等我的消息”。这个时候 Client 端就进入 FIN_WAIT 状态,继续等待 Server 端的 FIN 报文。当 Server 端确定数据已发送完成,则向 Client 端发送 FIN 报文,”告诉 Client 端,好了,我这边数据发完了,准备好关闭连接了”。Client 端收到 FIN 报文后,”就知道可以关闭连接了,但是他还是不相信网络,怕 Server 端不知道要关闭,所以发送 ACK 后进入 TIME_WAIT 状态,如果 Server 端没有收到 ACK 则可以重传。“,Server 端收到 ACK 后,”就知道可以断开连接了”。Client 端等待了 2MSL 后依然没有收到回复,则证明 Server 端已正常关闭,那好,我 Client 端也可以关闭连接了。Ok,TCP 连接就这样关闭了!
数据传输结束后,通信的双方都可释放连接,A 和 B 都处于 ESTABLISHED 状态。(A、B 连接建立状态 ESTABLISHED——A 进入等待 1 状态 FIN-WAIT-1——B 关闭等待状态 CLOSE-WAIT——A 进入等待 2 状态 FIN-WAIT-2——B 最后确认状态 LAST-ACK——A 时间等待状态 TIME-WAIT——B、A 关闭状态 CLOSED)
总而言之:
2MSL后自动进入CLOSED状态。该流程中让人比较困惑的问题是:
TIME_WAIT,这个时间要足够长,长到如果B没有收到ACK,B可以重试且时间足够到达。FIN 的 ACK,怎么办呢?按照 TCP 的原理,B 当然还会重发 FIN,这时A再收到这个包后,会直接返回RST,B就知道早已断开连接了。上面的握手和挥手流程汇总为状态机如下图所示:
TCP中并不是发1收1,而是使用一个缓冲区保存数据包,这个缓冲区称为窗口,发送端的发送窗口如下图所示:
为什么会有第3和第4部分?难道这些不都是等待发送的吗?其实区分第3和第4部分的主要目的是流量控制,在 TCP 里,接收端会给发送端报一个窗口的大小,叫 Advertised window。这个窗口的大小应该等于上面的第2部分加上第3部分,超过了这个窗口的接收端处理不过来,就不发送了,作为第4部分。
接收端同样也有一个接收窗口:
TCP中的重发有两种:
当发送未确认窗口中最早的一个包接收到了确认,则窗口将前移一格:
上图中,5接收到了确认,此时窗口前移一格,第14个包可以发送了。
如果接收方处理太慢,导致缓存中没有空间了,可以通过确认信息修改窗口的大小,甚至可以设置为 0,则发送方将暂时停止发送。
假设一个极端情况,接收端的应用一直不读取缓存中的数据,当数据包 6 确认后,窗口大小就不能再是 9 了,就要缩小一个变为 8。
那么缩小后什么时候恢复呢?发送方会定时发送窗口探测数据包,看是否有机会调整窗口的大小。
拥塞控制也是通过控制窗口大小来实现的,前面的滑动窗口 rwnd 是怕发送方把接收方缓存塞满,而拥塞窗口 cwnd,是怕把网络塞满。
TCP的拥塞控制主要是为了避免丢包和超时重传问题:
如果窗口不经控制——像UDP那样——很有可能发送的数据量超过中间设备的承载能力,多出来的包就会被丢弃,即发生了丢包,这是我们不希望看到的。
如果在这些设备上加缓存,处理不过来的先保存在缓存队列里,这样虽然不会丢失,但是会增加时延,如果时延达到一定程度,就会导致超时重传。
慢启动(指数增长)
刚开始不清楚网络情况,因此发送数据包时一次只能发1个,后来按2、4、8的指数性增长速度来增长;
线性增长
当超过一个阈值ssthresh=65535时,可能速度达到了网络性能,这时会慢下来,变成线程增长,每收到一个确认后,cwnd才会增加1/cwnd。
指数递减
当发生了丢包,需要超时重传时,会设置ssthresh=cwnd/2,并将cwnd设置为1,重新开始慢启动,这种减速方式的问题是太过激进,从原来的高速马上减到1,会造成明显的网络卡顿,因为这个问题,一般会采用快速重传算法。
快速重传算法
当接收端发现丢了一个中间包的时候,发送三次前一个包的 ACK,于是发送端就会快速地重传,不必等待超时再重传。
TCP 认为这种情况不严重,因为大部分没丢,只丢了一小部分,cwnd 减半为 cwnd/2,然后 sshthresh = cwnd,当三个包返回的时候,cwnd = sshthresh + 3,也就是说没有立刻减到1。
不懂很多网络概念,在一些开会、对接场合出了很多洋相,趁机好好补补。
两者最核心的区别在于 apache 是同步多进程模型,一个连接对应一个进程,而 nginx 是异步的,多个连接(万级别)可以对应一个进程
一般来说,需要性能的 web 服务,用 nginx 。如果不需要性能只求稳定,更考虑 apache ,后者的各种功能模块实现得比前者,例如 ssl 的模块就比前者好,可配置项多。epoll(freebsd 上是 kqueue ) 网络 IO 模型是 nginx 处理性能高的根本理由,但并不是所有的情况下都是 epoll 大获全胜的,如果本身提供静态服务的就只有寥寥几个文件,apache 的 select 模型或许比 epoll 更高性能。当然,这只是根据网络 IO 模型的原理作的一个假设,真正的应用还是需要实测了再说的。
更为通用的方案是,前端 nginx 抗并发,后端 apache 集群,配合起来会更好。
通过研究接入层的发展历程,我们可以一窥 Nginx 在互联网架构中的地位。

可以看到,每一个下游都有多个上游调用,只需要做到,每一个上游都均匀访问每一个下游,就能实现整体的均匀分摊。
session 不推荐放到站点层,后期扩展会有问题,更好的方案是放到数据层。

/var/temp/nginx1 | ./configure \ |
1 | make |
/etc/profile中编辑,这样就可以直接使用 nginx 命令启动了1 | export PATH=$PATH:/usr/local/nginx/sbin |
1 | nginx |
1 | nginx -s stop # 相当于先查出nginx进程id再kill |
1 | nginx -s quit |
1 | nginx -s reload |
/etc/init.d/nginx1 | #!/bin/bash |
1 | chmod a+x /etc/init.d/nginx |
/etc/rc.local中加入一行1 | /etc/init.d/nginx start |
手动进行 Nginx 配置十分繁琐,可以使用 Docker 来简化部署流程:
1 | docker run -d -p 80:80 nginx |
Nginx 的代码是由一个核心和一系列的模块组成的。
核心主要用于提供 WebServer 的基本功能,以及 Web 和 Mail 反向代理的功能;还用于启用网络协议,创建必要的运行时环境以及确保不同的模块之间平滑地进行交互。
不过,大多跟协议相关的功能和应用特有的功能都是由 nginx 的模块实现的。
换句话说, 每一个功能或操作都由一个模块来实现。
这些功能模块大致可以分为事件模块、阶段性处理器、输出过滤器、变量处理器、协议、upstream 和负载均衡几个类别,这些共同组成了 nginx 的 http 功能。
事件模块主要用于提供 OS 独立的(不同操作系统的事件机制有所不同)事件通知机制如 kqueue 或 epoll 等。
协议模块则负责实现 nginx 通过 http、tls/ssl、smtp、pop3 以及 imap 与对应的客户端建立会话。
在 Nginx 内部,进程间的通信是通过模块的 pipeline 或 chain 实现的。
换句话说,每一个功能或操作都由一个模块来实现。例如:压缩、通过 FastCGI 或 uwsgi 协议与 upstream 服务器通信、以及与 memcached 建立会话等。
一个 Nginx 服务器实例由一个 master 进程和多个 worker 进程组成。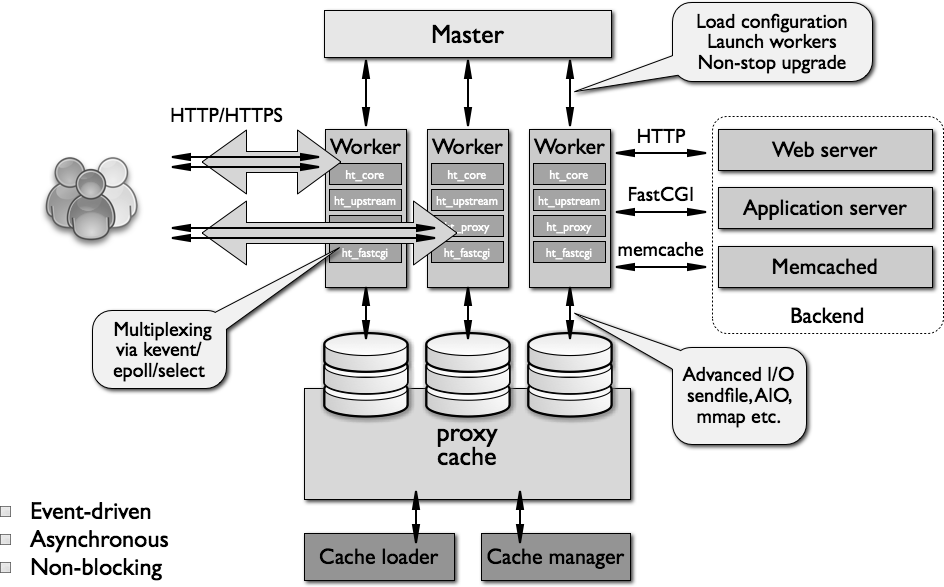
master进程主要用来管理 worker 进程,还有一些对整个服务器的初始化和日志记录等工作。
管理 worker 的过程:接收来自外界的信号,向各 worker 进程发送 信号 ,监控 worker 进程的运行状态,当 worker 进程退出后(异常情况下),会自动重新启动(fork)新的 worker 进程。
master 主要功能:
对请求的实际处理由 worker 负责,且每个请求只能由一个 worker 负责(一对一)。在启动时,创建一组初始的监听套接字,HTTP 请求和响应之时,worker 连续接收、读取和写入套接字。
worker 主要功能:
nginx 启动后,在 unix 系统中会以 daemon 的方式在后台运行,后台进程包含一个 master 进程和多个 worker 进程(你可以理解为工人和管理员)。
nginx 不会为每个连接派生进程或线程,而是由 worker 进程通过监听共享套接字接受新请求,并且使用高效的 循环 来处理数千个连接。
Nginx 不使用仲裁器或分发器来分发连接,这个工作由操作系统内核机制完成。 监听套接字 在启动时就完成初始化,worker 进程通过这些套接字接受、读取请求和输出响应。
一次请求过程大概执行过程为:
在 Nginx 内部,进程间的通信是通过模块的 pipeline 或 chain 实现的,其原理是信号机制,master 对 worker 进程采用信号进行控制。
所谓事件驱动架构,简单来说,就是由一些事件发生源来产生事件,由一个或多个事件收集器(epolld 等)来收集、分发事件,然后许多事件处理器会注册自己感兴趣的事件,同时会“消费”这些事件。nginx 不会使用进程或线程作为事件消费者,只能是某个模块,当前进程调用模块。
传统 web 服务器(如 Apache)的所谓事件局限在 TCP 连接建立、关闭上,其他读写都不再是事件驱动,这时会退化成按序执行每个操作的批处理模式,这样每个请求在连接建立后都将始终占用系统资源,直到连接关闭才会释放资源。大大浪费了内存、cpu 等资源。并且把一个进程或线程作为事件消费者。 传统 Web 服务器每个事件消费者独占一个进程资源,相对来说,Nginx 只是被事件分发者进程短期调用而已。
nginx 采用多 worker 的方式来处理请求,每个 worker 里面只有一个主线程,那能够处理的并发数很有限,多少个 worker 就能处理多少个并发,那么何来的高并发呢?
其实,Nginx 是采用了异步非阻塞的 IO 模型来处理请求的(epoll),异步的概念是和同步相对的,也就是不同事件之间不是同时发生的。非阻塞的概念是和阻塞对应的,阻塞是事件按顺序执行,每一事件都要等待上一事件的完成,而非阻塞是如果事件没有准备好,这个事件可以直接返回,过一段时间再进行处理询问,这期间可以做其他事情。
请求的多阶段异步处理只能基于事件驱动框架实现,就是把一个请求的处理过程按照事件的触发方式分为多个阶段,每个阶段都可以有事件收集、分发器(epoll 等)来触发。比如一个 http 请求可以分为七个阶段。
每种事件都有一个事件队列,按触发的先后顺序处理。
惊群是多个子进程在同一时刻监听同一个端口引起的;
Nginx 解决方法:同一个时刻只能有唯一一个 worker 子进程监听 web 端口,此时新连接事件只能唤醒唯一正在监听端口的 worker 子进程。这可以通过锁或互斥量实现。
ngx_http_[module-name]_[main|srv|loc]_conf_t
前缀表示模块名,后面表示模块运行在哪一层
Nginx由内核和一系列模块组成,内核提供web服务的基本功能,如启用网络协议,创建运行环境,接收和分配客户端请求,处理模块之间的交互。Nginx的各种功能和操作都由模块来实现。
Nginx的模块从结构上分为核心模块、基础模块和第三方模块。
这样的设计使Nginx方便开发和扩展,也正因此才使得Nginx功能如此强大。Nginx的模块默认编译进nginx中,如果需要增加或删除模块,需要重新编译Nginx,这一点不如Apache的动态加载模块方便。如果有需要动态加载模块,可以使用由淘宝网发起的web服务器Tengine,在nginx的基础上增加了很多高级特性,完全兼容Nginx,已被国内很多网站采用。
模块大致结构如下图所示。
Nginx模块,简单地讲,就是:在特定地方调用的函数。
nginx的配置 指令作用域 分为以下几种:main,server,location
main作用域的范围为整个配置文件,而server是指某个具体的服务器(通过端口号来区分),而location就是指要访问这个server的哪个location。
Nginx 本身做的工作实际很少,当它接到一个 HTTP 请求时,它仅仅是通过查找配置文件将此次请求映射到一个 locationblock,而此 location 中所配置的各个指令则会启动不同的模块去完成工作。
通常一个 location 中的指令会涉及一个 handler 模块和多个 filter 模块(当然,多个 location 可以复用同一个模块)。handler 模块负责处理请求,完成响应内容的生成,而 filter 模块对响应内容进行处理。
模块处理请求的大致过程如下图所示。
定义将要被作为默认页的文件。 文件的名字可以包含变量。 文件以配置中指定的顺序被 nginx 检查。 列表中的最后一个元素可以是一个带有绝对路径的文件。
1 | location / { |
需要注意的是,index 文件会引发内部重定向,请求可能会被其它 location 处理。
比如下面的配置,请求”/“实际上将会在第二个location中作为”/index.html”被处理:
1 | location = / { |
1 | log_format gzip '$remote_addr-$remote_user[$time_local]' |
指令 access_log 指派路径、格式和缓存大小:
1 | # 格式 |
其中参数 “off” 将清除当前级别的所有 access_log 指令。如果未指定格式,则使用预置的 “combined” 格式。缓存不能大于能写入磁盘的文件的最大值(在 FreeBSD 3.0-6.0 ,缓存大小无此限制)。
指令 log_format 指定日志格式:
1 | # 格式 |
此模块提供了一个简易的基于主机的访问控制。
ngx_http_access_module 模块让我们可以对特定 IP 客户端进行控制。 规则检查按照第一次匹配的顺序,此模块对网络地址有放行和禁止的权利。
1 | # 仅允许网段 10.1.1.0/16 和 192.168.1.0/24 中除 192.168.1.1 之外的 ip 访问 |
1 | allow [ address | CIDR | all ] |
1 | deny [ address | CIDR | all ] |
执行 URL 重定向,允许你去掉带有恶意的 URL,包含多个参数(修改).利用正则的匹配,分组和引用,达到目的 配置范例:该模块允许使用正则表达式改变 URL,并且根据变量来转向以及选择配置
1 | if (condition) { ... } |
1 | if ($http_user_agent ~ MSIE) { |
1 | return cod |
1 | rewrite regex replacement flag |
此模块能代理请求到其它服务器.也就是说允许你把客户端的 HTTP 请求转到后端服务器(这部分的指令非常多,但不是全部都会被用到,详细指令列表可以上官网查看,这里是比较常见的指令简介)
1 | # 强制一些被忽略的头传递到客户端 |
该指令将来自客户端的一个请求分到多个上行服务器上,即我们常说的负载均衡。
默认情况下采用轮询策略,每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。
可以使用weight来指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况。
1 | upstream backend { |
1 | upstream backend { |
1 | upstream test{ |
1 | upstream backend { |
1 | upstream backend { |
1 | upstream backend { |
1 | upstream backend { |
默认配置文件位置在/usr/local/nginx/conf/nginx.conf,在configue时决定,也可以在运行nginx时指定配置文件
1 | nginx nginx.conf |
顶层配置即nginx.conf中前面、暴露在外面的那几项
1 | #user nobody; |
worker_processes 定义了 nginx 在为你的网站提供服务时,worker 进程的数量。
这个优化值受到包括 CPU 内核数、存储数据的磁盘数、负载值在内的许多因素的影响。如果不确定的话,将其设置为可用的 CPU 内核的数量是一个不错的选择(设置为“auto”,将会尝试自动检测可用的值)。
另外本机的CPU核心信息可以使用下面命令查看
1 | cat /proc/cpuinfo | grep processor |
events模块包括了 nginx 中处理链接的全部设置
1 | events { |
worker_connections 设置了一个 worker 进程可以同时打开的链接数。
multi_accept 的作用是告诉 nginx 在收到新链接的请求通知时,尽可能接受链接。最好开着
当外部有 http 请求时,nginx 的 http 模块才是处理这个请求的核心。
略…
1 | user nginxuser; |
默认配置下,Linux 只支持有限的连接数。
Linux 的线程其实是一个进程,所以 java 的也是,具体来说,叫做“light weight process(LWP)”—轻量级进程。
LWP 与其它进程共享所有(或大部分)逻辑地址空间和系统资源,一个进程可以创建多个 LWP,这样它们共享大部分资源;LWP 有它自己的进程标识符,并和其他进程有着父子关系;。LWP 由内核管理并像普通进程一样被调度
使用以下命令可以看到某个用户使用了多少进程资源
1 | ps -eLf | grep xjjbot(uid) | wc -l |
使用下面命令可以查看具体每个进程开启了多少线程
1 | ps -o nlwp,pid,lwp,args -u xjjbot(uid) | sort -n |
根据 linux 一切都是文件的规则,首先想到的,是修改 ulimit 的参数,然而也不是,因为它已经足够大了。交叉回想一下 elasticsearch,在安装的时候,需要配置一个叫做 nproc 的东西,问题大概就出在这,是进程资源不够用啦。
相关的配置文件:
1 | /etc/security/limits.conf |
在不同的内核版本上,也有一些小差异。比如:/etc/security/limits.d/*
下的文件,会在某些时候覆盖 limits.conf 的配置。所以配置不生效的情况下,记得检查一下。
鉴于以上原因,可以将 limits.d 中的配置全部注释掉,统一在 limits.conf 中配置。
以下是原始配置
1 | * soft nproc 4096 |
将 4096 改为大点的数字,或者直接改成 unlimited 就可以了。
单机支持 100 万连接是可行的,但带宽问题会成为显著的瓶颈。启用压缩的二进制协议会节省部分带宽,但开发难度增加。
更改进程最大文件句柄数
1 | ulimit -n 1048576 |
复制代码修改单个进程可分配的最大文件数
1 | echo 2097152 > /proc/sys/fs/nr_open |
复制代码修改/etc/security/limits.conf 文件
1 | * soft nofile 1048576 |
复制代码记得清理掉/etc/security/limits.d/*下的配置
打开/etc/sysctl.conf,添加配置然后执行,使用 sysctl 生效
1 | #单个进程可分配的最大文件数 |
nginx.conf配置文件详解 http://www.ha97.com/5194.html
更多配置技巧 https://www.nginx.com/resources/wiki/start/
这一篇是对在公司内缓存代码应用 Redis-Lua 的一个总结,经过 benchmark 测试,这种方式效率更高,且理论上有更低的可能性。
顺便,一开始先描述一下Redis中的事务的原理,因为Redis-Lua本身是事务的一个替代品,这二者一般放在一起讨论。
收集从网上找到的学习资料,大部分来自 Github。
云环境下自适应负载均衡算法的设计。
题目描述 -> 阿里巴巴 2019 中间件性能挑战赛-自适应负载均衡(初赛)赛题
抽不出时间,中途放弃了。
不同于 C++中的泛型,Java 的泛型会在编译后被清除,这种机制被称为泛型擦除。
java 的类型推断基本都在编译期完成
优点:可以免去大量的显式类型转换;
缺点:由于泛型擦除的存在,在很多场合下容易引起误会:
枚举可以使用 enum 声明,在 switch 中可以作为 case 后的标签。可以使用 EnumMap 来保存枚举到其他类型的映射或使用 EnumSet 保存枚举值的集合。
优点:
基本类型可以自动转换成对应的包装类型,比如 boolean 会被包装为 Boolean。
优点:
缺点:
可以传入任意多个相同类型的参数。
优点:
缺点:
注解需要和反射配合使用,JDK 提供了一些具有特定语义的注解:
@Inherited:是否对类的子类继承的方法等起作用;
@Target:作用目标;
@Rentation:表示 annotation 是否保留在编译过的 class 文件中还是在运行时可读。
优点:
缺点:
可以直接使用一个类中的静态方法。
缺点:
提供对日期、数字等的格式化支持
1 | public class ThreadingTest extends Thread { |
1 | Arrays.sort(myArray); |
返回类型可以是父类中相应类型或其子类。
JRE installer 能将一些系统 jar 文件加载到一种私有内部表示方式,然后转储到一个文件内,称为“shared archive”,下次启动应用的时候可以直接使用这个包内的类数据,这样可以减少部分启动时间。
如果机器至少有 2 CPUs 和至少 2GB 物理内存,use the Java HotSpot Server Virtual Machine (server VM) instead of the Java HotSpot Client Virtual Machine (client VM).,The aim is to improve performance even if no one configures the VM to reflect the application it’s running. In general, the server VM starts up more slowly than the client VM, but over time runs more quickly.
服务器类机器默认垃圾回收器改为并行垃圾回收器。
可以指定性能目标,并行收集器可以自动调整堆的大小,比如:
1 | -XX:GCTimeLimit=time-limit :花费在GC上的时间上限,默认是98,当超过上限时,会抛出OutOfMemory(HeapSpace)的异常 |
Thread 类中给出了三个线程优先级常量:
1 | java.lang.Thread.MIN_PRIORITY = 1 |
默认情况下线程优先级为 java.lang.Thread.NORM_PRIORITY,我们可以自定义设置在[1..10]内。
JVM(Java HotSpot)将 Java 线程关联到唯一的一个 native thread。
IP 地址是在网络层封装上的,确定 Internet 上的一个唯一的地址,端口号是由传输层封装上的,标志主机上的一个服务。
1 | public class InetAddressTest { |
UrlConnection 可以从一个 URL 中打开流,可以方便地进行 Http 数据的收发。
内部是使用 Socket 进行连接的。
1 | // 获取链接属性 |
访问链接
1 | // 访问链接读取数据 |
下面是对 URLConnection 的测试:
1 | public class URLTest { |
它们都是位于传输层的协议,为应用进程提供服务,根据不同的应用场景,会使用不同的协议。
TCP 是基于连接的、面向流的协议,提供可靠通信,因此每次通信必须先建立连接,建立连接后可以分多次进行传输任务,并且保证数据的正确性。
UDP 是基于无连接的、面向数据报的协议,提供不可靠通信,每次通信只需要发送一次数据报,可以分多次发送,但不保证能否到达、到达的顺序。
Socket 是 TCP 的应用编程接口,DatagramSocket 是 UDP 的应用编程接口,他们之间没有继承关系(都实现 Closeable 接口)。
Socket 使用时需要先指定目标主机地址和端口号,然后打开 io 流进行操作
1.服务端
1 | // 监听8080端口 |
2.客户端
1 | // 监听8080端口 |
缓冲(Buffer):相当于货物
管道(Channel):相当于配货车,支持同时装多件货物。
选择器(Selector):是 SelectableChannel 的多路复用器。用于监控 SelectableChannel 的 IO 状况。相当于中转站的分拣员。
服务端:
1 | // 创建服务器socket,指定端口 |
客户端:
1 | DatagramSocket socket = new DatagramSocket(); |
1 | // 发送 |
主要思路很简单:
(1) 服务器打开后首先为 Selector 注册一个 OP_ACCEPT 的 key,这样 select 时就能接收客户端请求了;
(2) 每接收一个请求后即为该 key 创建一个线程,处理该 key 的操作,操作包括 accept 和 read,对于前者,只需为该 key 的 selector 再注册一个 OP_READ 用于准备接下来的读请求;
(3) 读取时先读入一个 Buffer,首先解析请求头部分,直到遇到一个空行结束,因为这里只考虑 GET 请求,所以不必继续解析请求体了;
(4) 返回时,首先构建响应头,同样使用一个空行结束,然后构建响应体,写回客户端,结束。
1 | public class HttpServer { |
声明数据结构
1 | // 管道、选择器、字符集 |
创建线程类用于从服务端获取数据
1 | private class ClientThread extends Thread { |
初始化
1 | // 初始化SocketChannel |
创建线程从服务端拉取数据,及不断从键盘读入发送到服务端
1 | // 启动线程不断从服务端拉取 |
声明
1 | // 选择器、字符集 |
初始化
1 | // 打开管道 |
接受连接,读取及发送数据
1 | // 依次处理选择器上的选择键 |