Human in Loop的几种实现方式
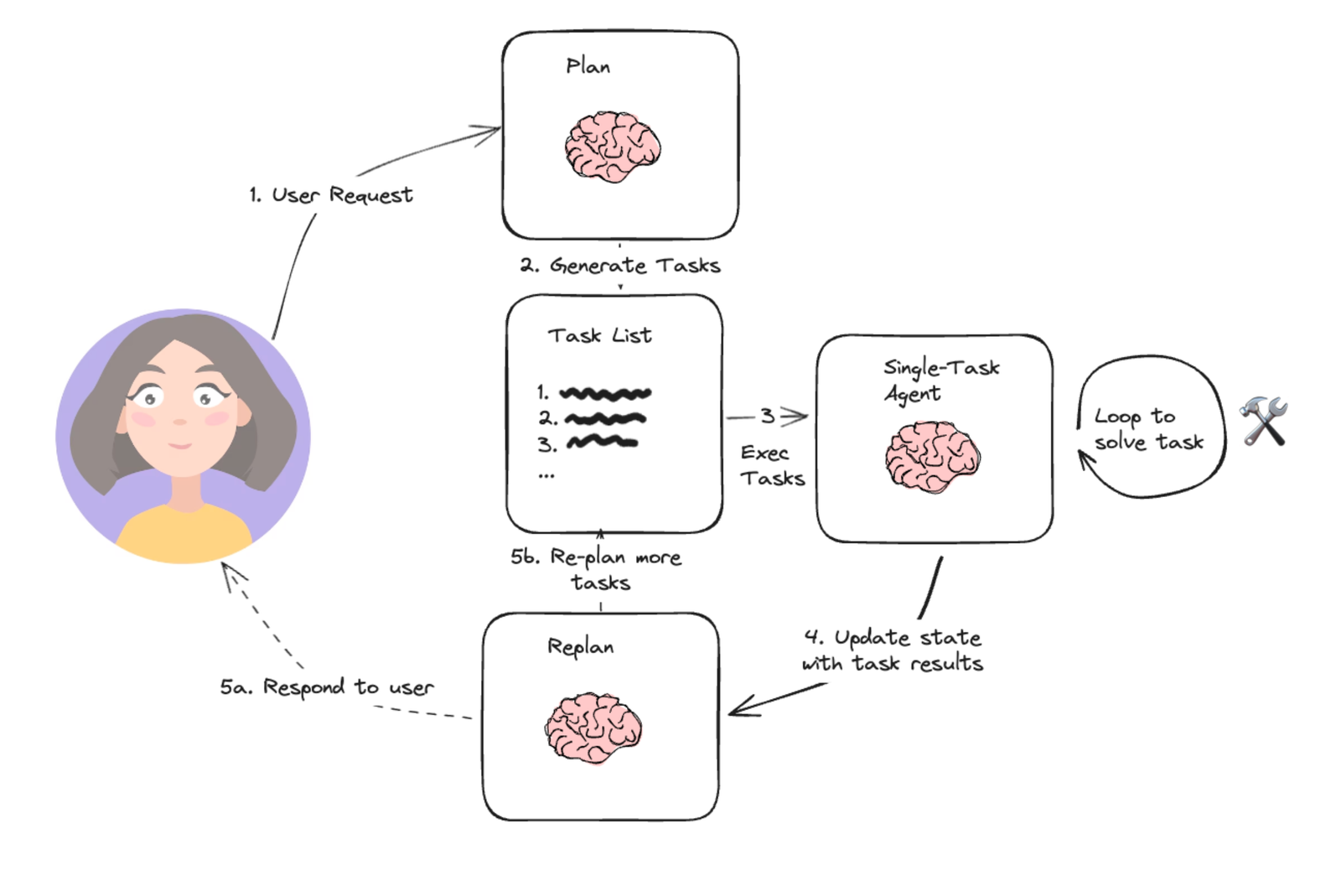
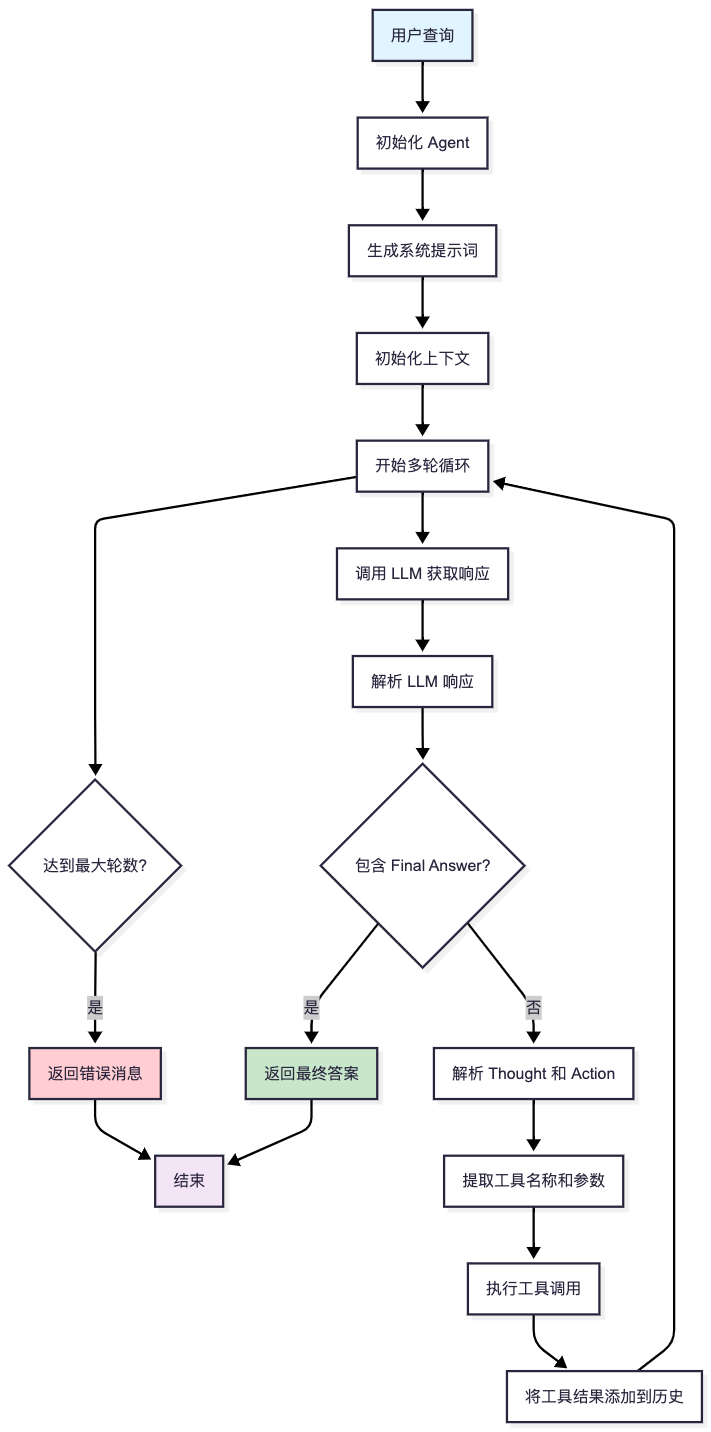
human-in-loop是指在agent的循环执行中,让人能够介入,从而让自动化流程中可以使用人这个工具来实现输入密码、授予权限等操作。
实现human-in-loop主要取决于两个能力:
- 阻塞通知能力,原地阻塞,等待用户输入,用户输入将通过事件通知的方式来触发流程的继续执行,例如:LlamaIndex和ADK的实现
- 中断恢复能力,在关键执行节点保存执行上下文,让任务能恢复执行,例如:LangGraph的实现
LangGraph的实现模式
LangGraph 中的人机循环工作流建立在 checkpoint 系统之上,使用检查点保存每一步的图形状态,并在人工干预后恢复。
中断原语
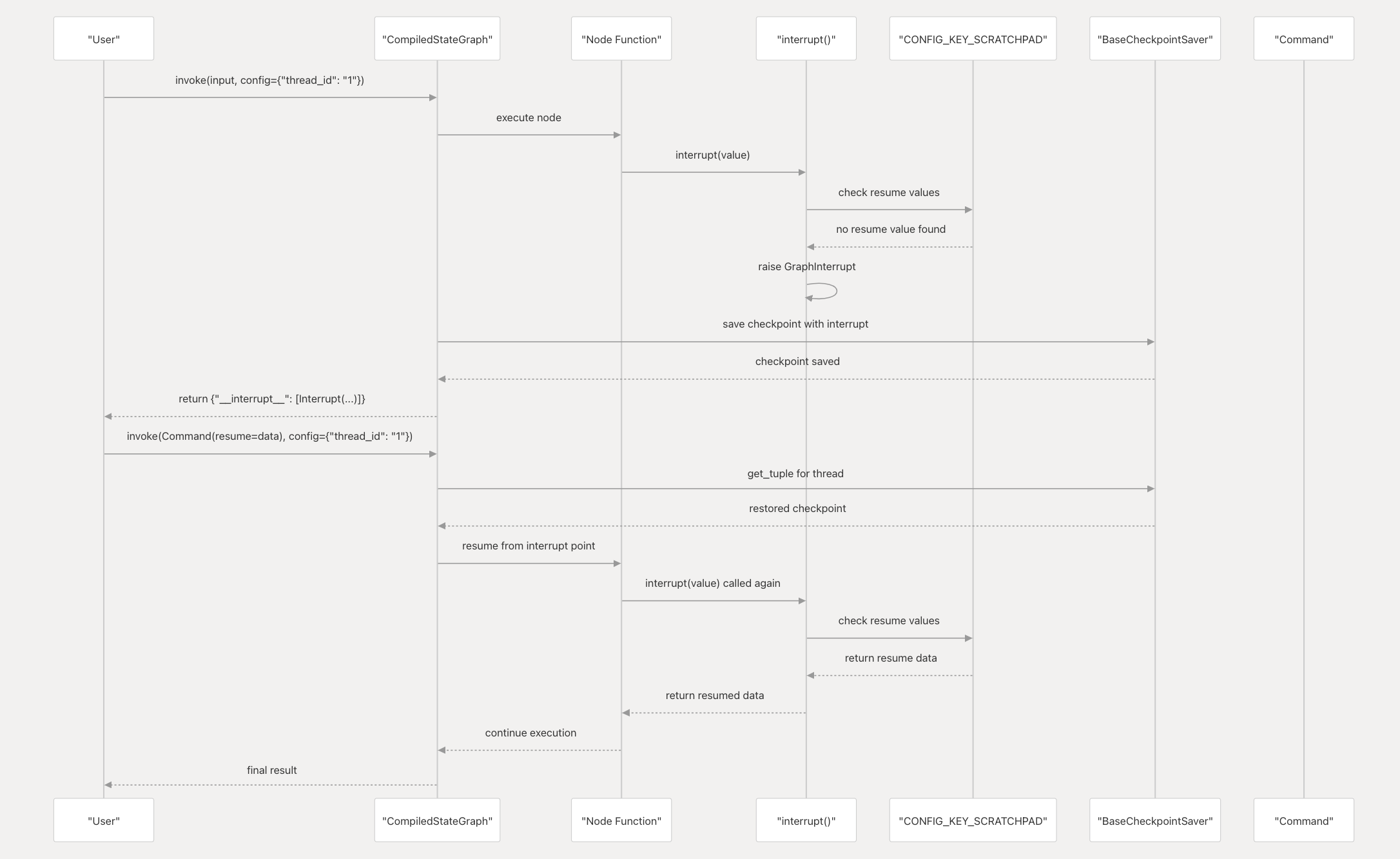
Common Patterns(常见模式)
LangGraph中的人机循环实现提供了几种常见的模式,用于不同的应用场景:
1. 审批或拒绝模式(Approve or Reject)

用于需要人工审批的场景,比如内容审核、决策确认等。
1 | def approval_node(state): |
2. 审查和编辑状态模式(Review and Edit State)
允许人工审查当前状态并进行编辑修改。
1 | def review_edit_node(state): |
3. 审查工具调用模式(Review Tool Calls)
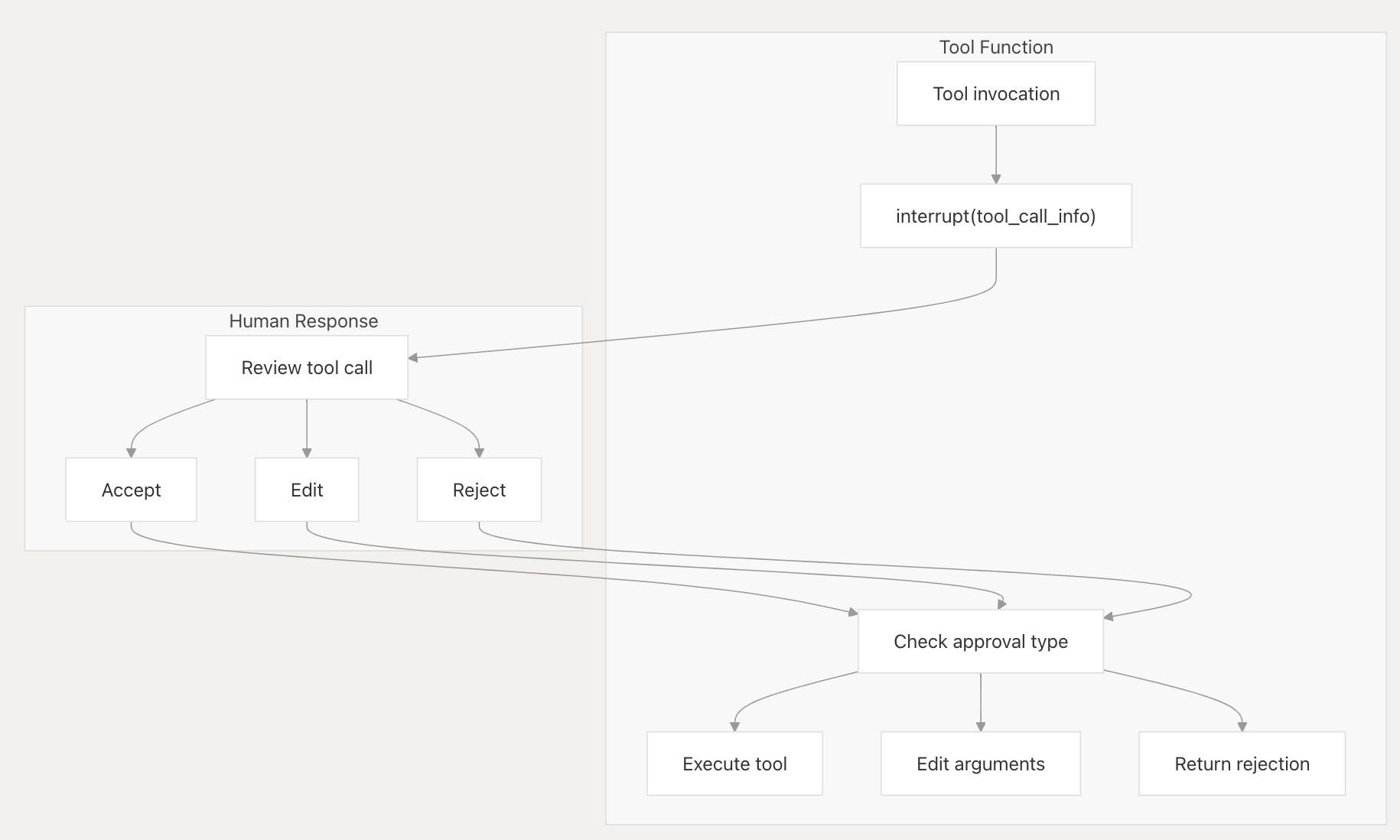
在工具执行前进行人工审查,确保工具调用的正确性。
1 | def tool_review_node(state): |
4. 为任何工具添加中断模式(Add Interrupts to Any Tool)
可以在任何工具执行前后添加人工干预点。
1 | def tool_with_interrupt(state): |
5. 验证人工输入模式(Validate Human Input)
对人工输入进行验证,确保输入的正确性和完整性。
1 | def validation_node(state): |
使用注意事项
1. 副作用处理
- 将带有副作用的代码(如API调用)放在
interrupt之后或单独的节点中 - 避免在中断点之前执行不可逆的操作
2. 子图调用
- 当子图作为函数调用时,父图会从调用子图的节点开始重新执行
- 子图会从包含
interrupt的节点开始重新执行
3. 单节点多中断
- 在单个节点中使用多个中断时,需要注意执行顺序
- 中断的匹配是基于严格索引的,顺序很重要
- 避免动态改变节点结构,可能导致索引不匹配
参考文档
https://deepwiki.com/langchain-ai/langgraph/4-human-in-the-loop-capabilities#common-hil-patterns
https://langchain-ai.github.io/langgraph/how-tos/human_in_the_loop/add-human-in-the-loop/#pause-using-interrupt
LlamaIndex
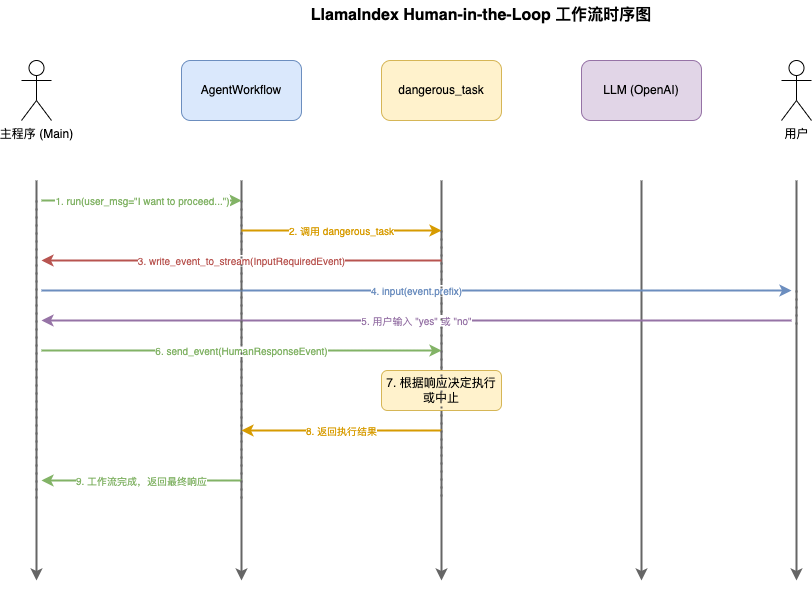
LlamaIndex会向外发送一个消息InputRequiredEvent事件,然后等待外部处理事件后回馈一个回执事件HumanResponseEvent
- 事件驱动:使用 InputRequiredEvent 和 HumanResponseEvent 进行异步通信
- 人工确认:危险操作需要用户明确确认(”yes” 或 “no”)
- 异步处理:使用 async/await 模式处理异步事件
- 流式处理:通过 stream_events() 实时处理事件流
参考文档
https://github.com/run-llama/python-agents-tutorial/blob/main/5_human_in_the_loop.py
https://docs.llamaindex.ai/en/stable/understanding/agent/human_in_the_loop/
ADK
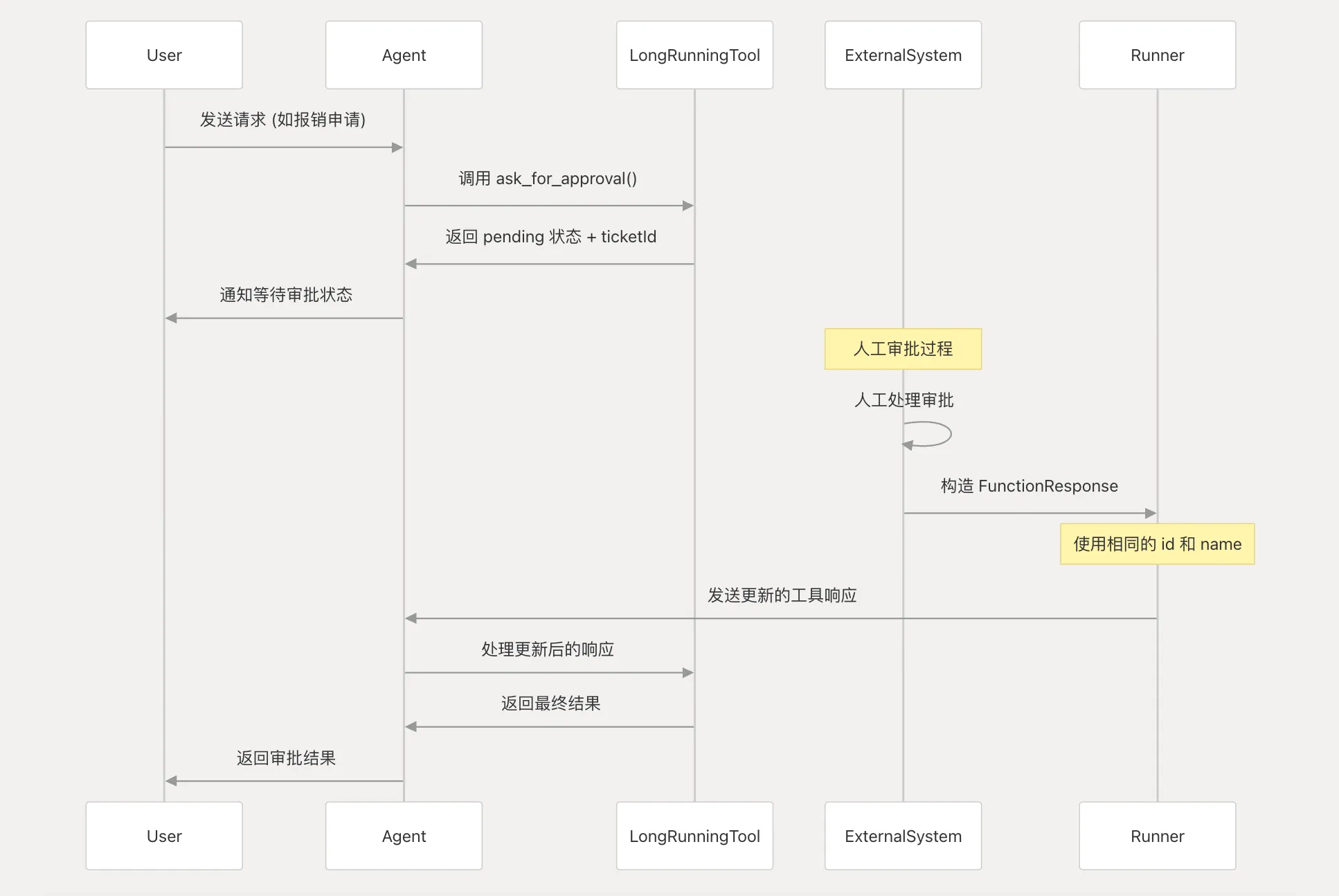
长时间运行工具(Long-Running Tools)
这是最直接的实现方式,使用LongRunningFunctionTool来处理需要人工干预的异步操作。
核心实现流程:
- 初始调用:Agent调用长时间运行工具,工具立即返回pending状态和跟踪ID
- 等待人工干预:系统等待外部人工处理
- 更新工具响应:人工处理完成后,必须构造新的types.FunctionResponse并发送给Agent
参考文档
https://deepwiki.com/search/human-in-the-loop_c1195076-6732-4fa2-97fe-4a4d444faec6
magentic-ui human in loop
connection.py定义用户输入函数:更新agent运行状态等待用户输入,然后阻塞等待用户输入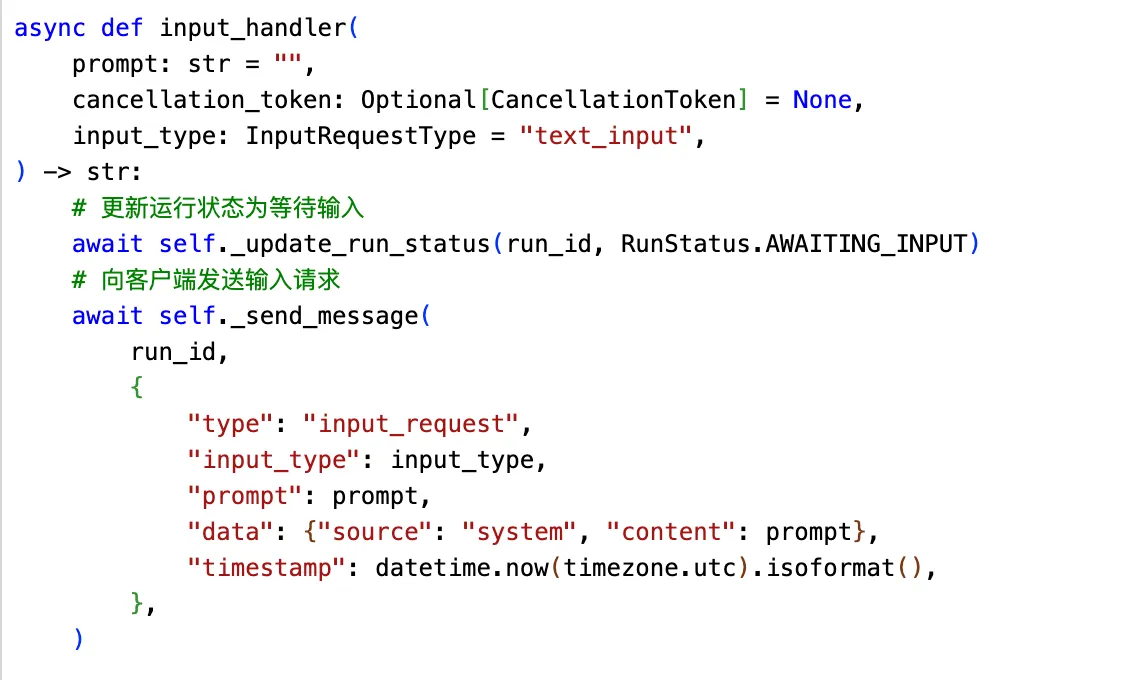

将user_input包装为Agent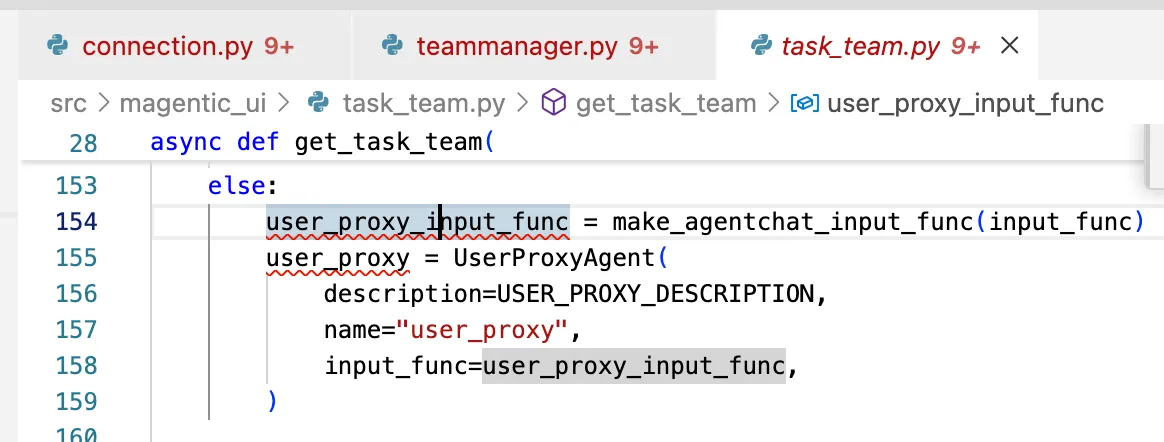
Agent作为team的参与者,被分发